How to Combine Relative Potencies for Bioassay
It often happens that the precision required from a relative potency (RP) bioassay cannot be achieved using a single plate. In this situation the usual approach is to repeat the assay two or more times1. Each run of the assay will give a separate relative potency result. These are then combined to give a single “reportable value”. This is supposed to be our best estimate of the true relative potency, given the individual measurements we have – but how exactly should it be calculated?
Both the USP (in section 4 of Chapter 1034) and the PhEur (in section 6 of Chapter 5.3) give guidelines for how to combine RPs. Each guideline discusses three methods – these have different names in the two guidelines, but are in fact very similar (although there are some differences which we’ll discuss). Here, we’ll discuss the pros and cons of each and how to choose the most appropriate method.
What’s the difference?
Let’s examine an example in order to illustrate the effects of the three methods.
Key Takeaways
- When combining relative potencies from multiple assay runs, weighted methods provide better estimates by giving more influence to precise measurements. The weighted heterogeneous method accounts for both intra- and inter-assay variation, making it the most reliable choice in most cases.
- If a statistically significant amount of inter-assay variation exists, the weighted heterogeneous method should be used. A statistical test can determine whether inter-assay variation is significant. If variation is negligible, the weighted homogeneous method is more appropriate.
- Older versions of USP and PhEur guidelines contain calculation errors for inter-assay variation. The PhEur formula underestimates variation, while the USP formula can sometimes produce invalid results. A correction (Hedges & Olkin method) should be applied to ensure accurate confidence intervals.
In this example, assay 3 is much less precise than the other two assays. The relative potency also happens to be lower.

Example
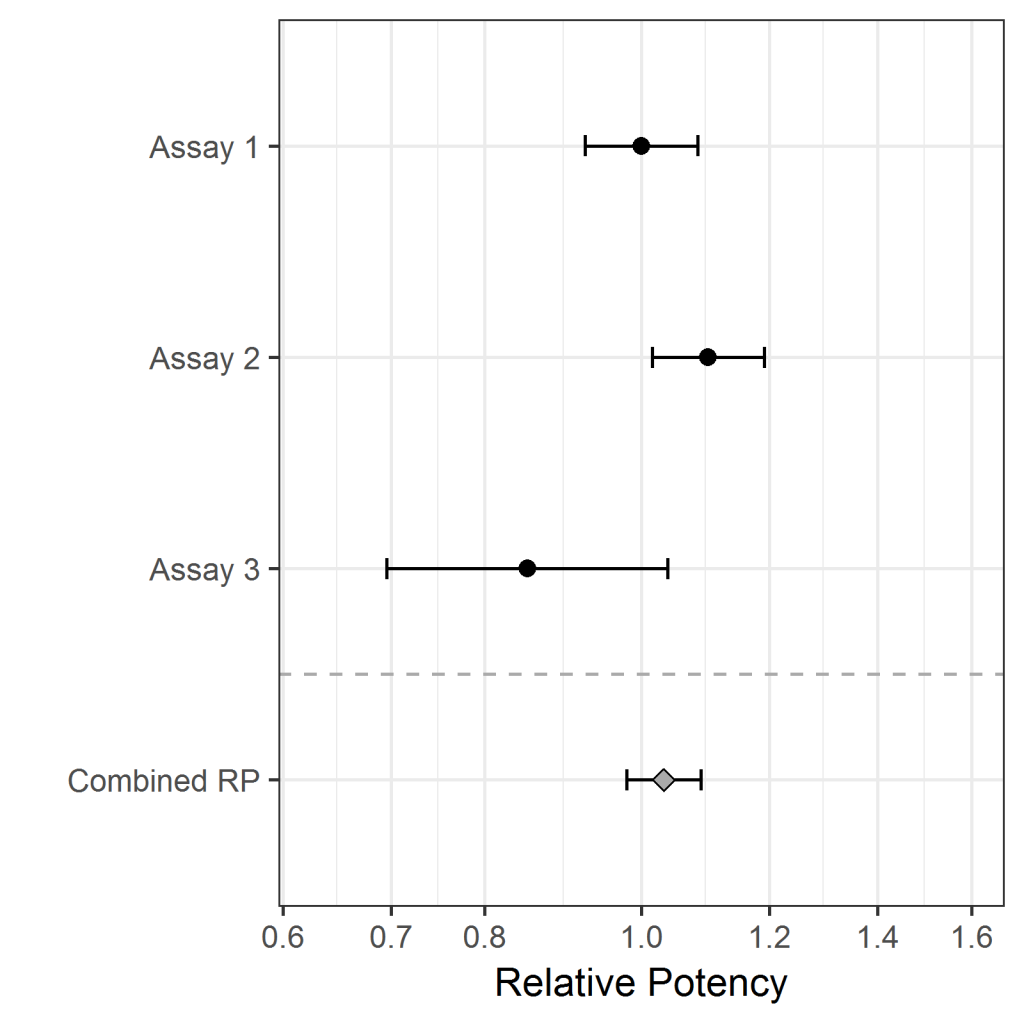
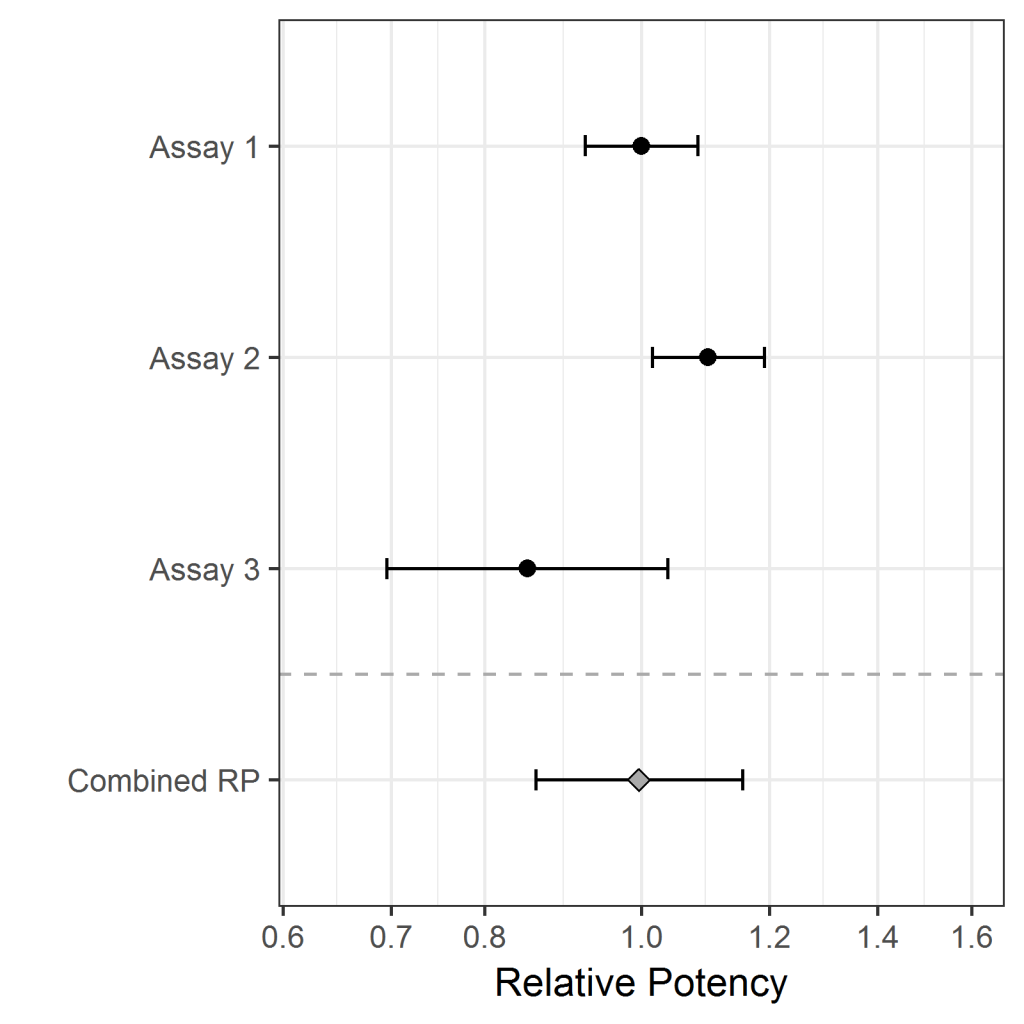
Below we show the results of combining the relative potencies of three assays using each of the three methods. For each method the three RPs are shown above the dotted line, with the error bars showing the 95% CIs; the wider the error bar, the less precise the measurement. The combined RP and its 95% CI is shown below the dotted line in each case.
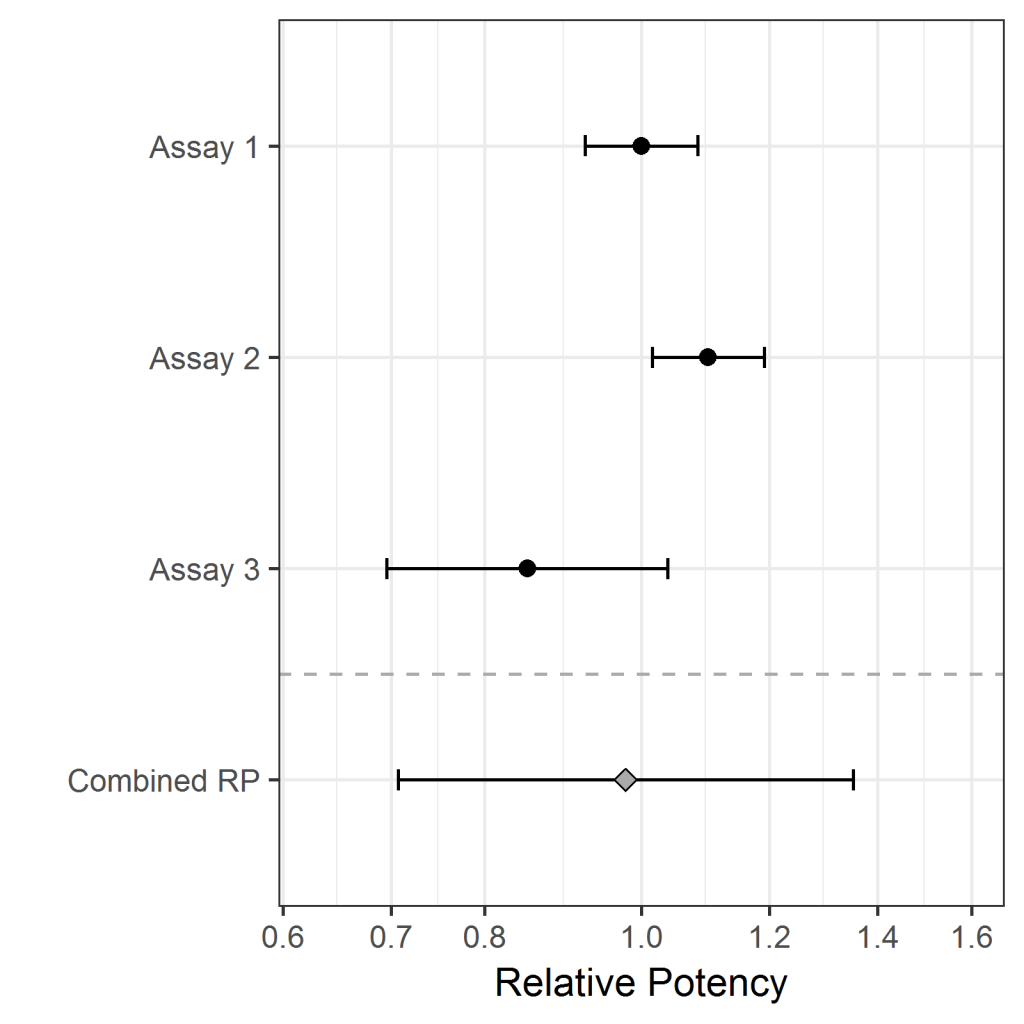
Method 1, unweighted combination, takes all three relative potencies into account equally, so the combined RP ends up being quite low – in fact, it is below the RPs for assay 1 and assay 2. But this does not seem quite right, because, assuming the assay is unbiased, we would expect that the more precise measurements, assays 1 and 2, are closer to the true RP, so the true RP is more likely to be somewhere between them.
The confidence interval for the combined result is also influenced by assay 3, making it (possibly) too wide in this example.
Method 2, weighted homogeneous combination, gives more weight to more precise results – those with narrower individual confidence intervals. Thus assays 1 and 2 have more influence on the combined estimate than assay 3 in this example. The confidence interval does not take account of the variation between the assay results, only the individual confidence interval widths, so the combined confidence interval in this case is possibly too narrow.
Method 3, weighted heterogeneous combination, also gives more weight to more precise results. Unlike method 2, the confidence interval takes account of the assay-to-assay variation as well as the individual confidence intervals. In this example, this would appear to be the most reasonable solution.
Which method is best?
It looks like Method 3 (the weighted heterogeneous method) takes everything into account – so should we always use it and forget about the other two? Possibly, but because it takes into account inter-plate variability, it gives CIs that are wider than those calculated by the weighted homogenous method. This is OK if there is real inter-assay variation, when it is appropriate for the CIs to be wider to reflect this. However, if in fact there isn’t any inter-assay variation, it could lead to unnecessarily wide CIs.
The conservative option is to use the weighted heterogeneous method anyway – since we can never be sure that there isn’t inter-assay variation, it is better to allow for it. Alternatively, a test can be used to test for inter-assay variation. If this gives a small p-value (say < 0.1) the weighted heterogeneous method should be used; otherwise, it is reasonable to conclude there isn’t any inter-assay variability so the weighted homogeneous method should be used. For the example above, the p-value is 0.026; thus the weighted heterogeneous method should be used.
On the other hand the unweighted method should never be used – it completely ignores the precision of the individual assays so can give very misleading CIs. It has been included in our QuBAS software simply because it is in the guidance.
Finally, a word of warning about the methods as discussed in the USP and PhEur
Note this has been fixed in the latest version of the guidance, but the error still exists in older versions.
During the development of the combining RPs module for our bioassay software QuBAS, we found that some aspects of the USP and PhEur guidance on this are incorrect. The problems arise in the calculations for method 3. The two methods give different formulas for calculating the inter-assay variation. The formula in the PhEur is incorrect: it does not account for the intra-assay variation, and is smaller by a factor of N (the number of assays) than it should be. This can lead to a severe underestimate of the inter-assay variation, which will lead to a CI for the combined RP that is too narrow.
The formula in the USP is generally correct, but it can cause problems in some situations. The formula given is:
\[(\text{Inter-Assay Variation})^2=S^2-\frac{1}{N}\sum(\text{Intra-Assay Variation)}^2\]
Where \(S\) is the standard deviation of the measured RPs on the log scale.
The problem is that sometimes the right-hand side of this equation is negative, and then it is impossible to take the square root to calculate the inter-assay variation. Fortunately there’s a simple fix: if the right-hand side turns out to be negative, we can just set the inter-assay variation to zero. This is called the Hedges and Olkin method (Hedges & Olkin 1985). So remember to use this to calculate the inter-assay variation.
All of this links with format variability as described in the USP chapter on assay validation (1033). In our next blog, we’ll write more about assay validation from a statistical point of view.
References
Hedges LV, Olkin I. 1985. Statistical Methods for Meta-Analysis. Orlando: Academic Press.
[1] Adjusting for plate effects, often known as row and column or edge effects, may help precision. See our blog