
R² II: What should you use to measure Goodness-of-Fit?
In the first part of this series, we investigated the use of the coefficient of determination—R2—to measure goodness-of-fit. Specifically, we showed that it is an inadequate tool: a low R2 does not always mean a poor model fit; a high R2 does not always mean a good model fit; and it doesn’t even measure the shape of our data in the first place.
This begs the question: what should we use to measure goodness-of-fit? Understanding model fit is vital throughout an assay’s life cycle, from choosing a model in development to ensuring that the data continues to fit that model in routine use. We’re going to highlight several better methods for checking goodness-of-fit so you can move away from R2 for good.
Visual Assessment
Key Takeaways
- Visual checks—plots of fitted curves and residuals—are powerful for spotting major and systematic fitting problems, even though they are not sufficient on their own for regulatory purposes.
- The F Test is straightforward and needs no historical data, but it can unfairly fail very precise assays and cannot be used when only pseudoreplicates are available.
- Equivalence testing, combined with “fitting the next model up”, offers a more robust way to assess goodness-of-fit, provided that meaningful equivalence limits can be set from historical assay performance.
Perhaps the simplest method for assessing goodness-of-fit is, well, looking at your data! While this is not accepted on its own by regulators, it is important for gaining a feel for your assay, which can help guide you when choosing next steps.
If a model is extremely poorly fit to a dataset, it will usually be quite clearly apparent when plotted. This can alert us to the most serious issues without the need for more complex statistical tests.
The kind of fitting failures which are immediately apparent in this way are typically rare, but that’s not where the benefits of visual assessment end. In part one, we mentioned a common problem: systematic over and under prediction by the fitted model. This is where the fitted model passes above or below a number of consecutive data points, and can sometimes be difficult to spot if your data is sparse.
By plotting the residuals of the data with respect to the fitted model, however, we can reveal patterns which would otherwise pass under our noses. Recall that a residual is the distance between a data point and a point of interest in the y-direction: we’re measuring how far above or below a point is from the model curve. If a data point is above the curve, then its residual is positive, and, if it’s below the curve, its residual is negative.
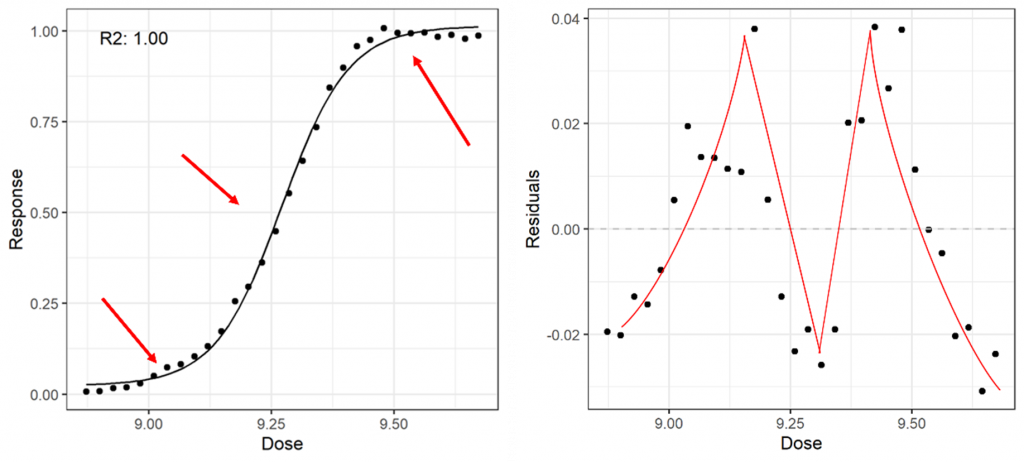
If a model fits the data well, then we should see very little pattern in the residuals. They should be fairly evenly distributed about 0, which is associated with random noise about a model. If we have a systematic fitting failure, however, we would expect to see a “zig-zag” pattern of consecutive groups of residuals above and below zero.
Figure 1 shows the residual plot of an example we highlighted in part one as having systematic fitting failures. There is a clear pattern here: the residuals are grouped in clusters above and below zero.
While examining the residuals is still a form of visual assessment—and not a regulator-approved metric of goodness-of-fit—it is another good way to detect problems with your model fit before embarking on more complex statistics. A pattern in the residuals is a sign that there is structure in your data which is not well represented by the model you’ve fitted.
As discussed in part I, this is the problem with R2: it does not measure the shape of a dataset. When we calculate R2, the information about the pattern of the residuals is lost as they are combined into a single number for the whole dataset. This is why a model with systematic fitting issues can have a high R2: it does not encapsulate the information which highlights the problem.
Statistical Goodness-of-Fit Testing
As we’ve mentioned, visual assessment is too subjective to be used as a suitability criterion. Eventually, we must always turn to statistics. We’re going to outline some of these statistical methods, as well as their strengths and weaknesses, to help you make informed decisions about what is right for you.
Method 1: The F Test
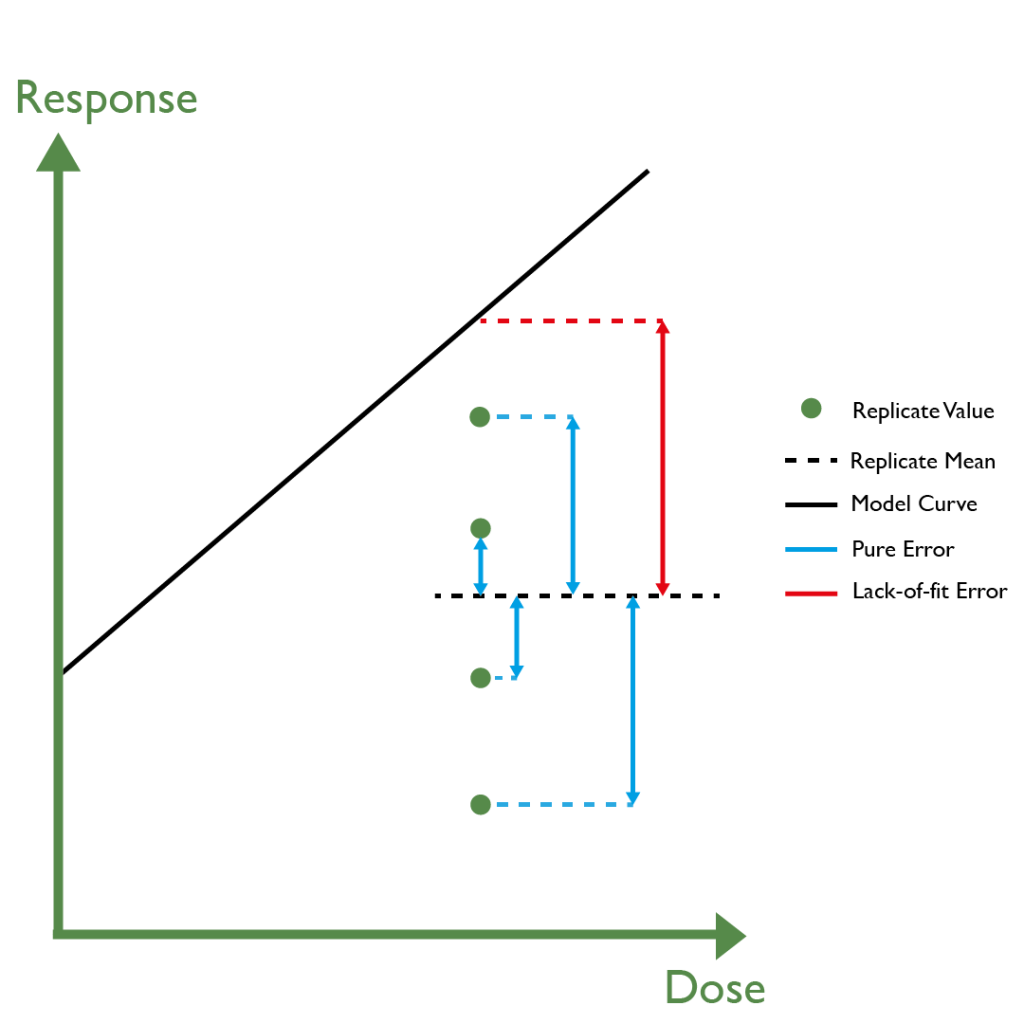
The F Test compares two types of error: the pure error and the lack-of-fit error. Let’s break this down: the pure error is the sum of the squared vertical distances between each of a group of replicates and the mean of that group. It’s a measure of how precise the assay is. The lack-of-fit error, on the other hand, measures how far away the replicate means are from the fitted value.
The F Test works out how much of the lack-of-fit error can be attributed to the pure error. In essence, it asks whether the lack-of-fit is because of the precision (or lack thereof) of the assay, or whether it is genuinely down to the model being a poor fit for the data. The output of the test is a p-value, which is compared to a pre-chosen significance level (typically 0.01 or 0.05). If the p-value is smaller than the significance level, the model fails the test.
So, do we have goodness-of-fit sorted? Let’s not get ahead of ourselves. To perform the F Test, we need to have more than one independent replicate at each dose. This could prove particularly problematic when using pseudoreplicates. As we’ve covered in detail elsewhere, pseudoreplicate responses are (or should be!) averaged into a single value before analysis. It is, therefore, often impossible to use the F Test when working with pseudoreplicates.
The F Test also has a quirk: it can sometimes incorrectly fail very precise assays, and this is becoming more of a problem with robotic liquid handlers. We’ve covered this before too, but, in essence, this happens because the pure error in such cases is very small, so the lack-of-fit error will always be large in comparison. This is what the F Test looks for as an indication of a poor fit, so models fit to very precise assay data can fail the test regardless of whether they are actually poorly fitting as would be judged by visual inspection.
Method 2: Fitting the “model up” & Equivalence Testing
What alternatives do we have? A different approach for measuring goodness-of-fit is to fit the “next model up”. The significance of the additional parameter can then be used as a criterion on the fit of the original model. For example, if you wanted to test the fit of a linear model, you could fit a quadratic model and test whether the coefficient of the quadratic term was significantly different from 0. Similarly, to test a 4PL, you can fit a 5PL and test whether the E parameter is significantly different from 1.
These checks can be performed using significance tests similar to the F Test—produce a p-value and compare to a pre-defined significance level—but the current regulator-preferred (recommended by USP and accepted by European regulators) method is equivalence testing. To pass an equivalence test, the confidence interval (CI, typically in the form of a 90% or 95% CI) of the criterion must fall entirely within a pair of chosen equivalence limits.
While significance testing asks whether a value can be considered statistically different from its target, equivalence testing asks a subtly different question: is it possible that the range of the value (as defined by the CI) falls acceptably close to the target, even if it might have failed a significance test? This “close enough” measure encapsulates what is acceptable, which is usually based on expected assay performance determined from historical data.
Let’s imagine we’re fitting a 4PL, and we want to check that a 5PL isn’t actually a better fit for our data. We fit the 5PL, and find that the E parameter value is 0.94 with a 95% CI of (0.89, 0.99). The CI does not contain 1, which is equivalent to the p-value of an F Test being less than 0.05.
Using a 0.05 significance level F Test to perform this check, we would determine that the E parameter is significantly different from 1. This implies that a 5PL would be more appropriate here than a 4PL.
Let’s imagine we’re fitting a 4PL, and we want to check that a 5PL isn’t actually a better fit for our data. We fit the 5PL, and find that the E parameter value is 0.94 with a 95% CI of (0.89, 0.99). The CI does not contain 1, which is equivalent to the p-value of an F Test being less than 0.05.
Using a 0.05 significance level F Test to perform this check, we would determine that the E parameter is significantly different from 1. This implies that a 5PL would be more appropriate here than a 4PL.
But what about with an equivalence test? If our equivalence limits were, say, (0.85, 1.15), then the CI would fall entirely within those limits. Whilst the E parameter is statistically significantly different from 1, it is close enough to 1 to be acceptable. This means that a 5PL model would, in this case, be considered as no better than our original choice of a 4PL.
Imagine we re-run the assay, and our data this time gives us a fitted E parameter of 0.87 with a 95% CI of (0.82, 0.92). The lower confidence limit would now be lower than the lower equivalence limit. This is evidence that our E parameter is not only significantly different from 1, but also not close enough to be acceptable. Therefore, a 5PL model would be a better fit for our data in this case.
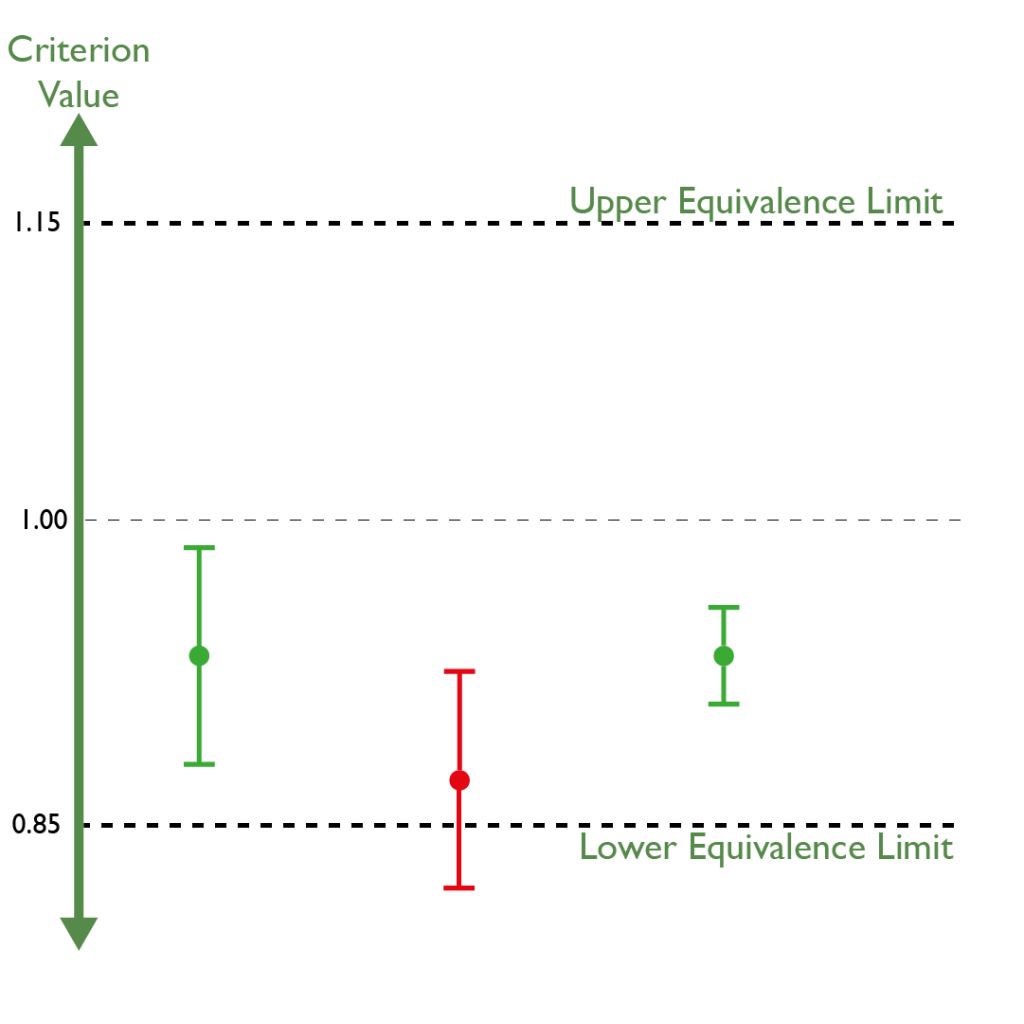
Importantly, equivalence testing does not have the same precision-penalising quirk as the F Test. A more precise assay would have a smaller CI on the test criterion, but this would not change whether a well-fit model passes the test. If the criterion’s CI lies entirely within the equivalence limits, then it would continue to do so if the CI was made narrower by increasing the precision of the assay.
However, every silver lining has a cloud, and the cloud here is the equivalence limits. In our example, we chose the equivalence limits arbitrarily, but, in reality, there is an involved process behind their setting.
As we mentioned earlier, setting equivalence levels requires large amounts of historical data to understand the performance of the assay and ensure that the set limits are meaningful. This means that equivalence testing may not be very useful in early assay development when there is little historical data about the performance of the assay. Even after validation, regulators expect that equivalence limits may change as more production data becomes available.
Choices, Choices
We have, therefore, two imperfect options. The F Test is simple to implement and requires no historical data, but it is liable to unnecessarily failing of very precise assays and can’t be used with pseudoreplicates. Conversely, equivalence testing solves these problems, but it is more complicated, requiring historical data analysis which simply may not be available early in the assay life cycle.
Which to choose? The answer will be different for every assay, and Quantics is, as always, on hand to help you find that answer should you need it. For now, though, we can provide some simple recommendations when it comes to dealing with goodness-of-fit. Perhaps most importantly, always ask yourself whether the data and fit you’re looking at makes sense. While visual assessment can never be enough of a goodness-of-fit test to satisfy the regulators, it is incredibly powerful for spotting fitting issues before implementing complicated statistical tests. The same goes for plotting residuals: it’s an incredibly simple tool, but one which produces results which can immediately—and clearly—highlight problems. And, no matter what, don’t use R2!







