Optimising Suitability Criteria for Bioassays
When running a bioassay, we face a constant battle between two competing requirements. The assay must be able to detect when something has gone wrong with the experiment or the product, but, simultaneously, must not be so sensitive that the assay fails frequently due to the natural variability of the biology at play in a bioassay. A key to achieving this fine balance is making strategic choices of suitability criteria, both in terms of the choice of test and the threshold for failure. Here, we’re going to highlight some common pitfalls we’ve encountered in our 20+ years of bioassay consultancy experience to help you optimise your next bioassay.
What are Suitability Criteria
Suitability criteria fall broadly into two categories: system suitability criteria and sample suitability criteria.
Key Takeaways
- Bioassays rely on both system suitability criteria (testing whether the assay is performing as expected) and sample suitability criteria (testing whether individual samples behave as expected), and both must be chosen carefully to keep failure rates under control.
- Using too many criteria, including criteria that measure the same underlying property, or applying inappropriate tests and thresholds (for example, F-tests in very precise assays or unstable parameter ratios) can dramatically and unnecessarily increase assay failure rates.
- Limiting the number of tests, avoiding redundant or poorly chosen criteria, and preferring alternatives such as equivalence tests or parameter differences instead of ratios can optimise assay performance and reduce wasted time, material, and cost.
System suitability criteria
System suitability criteria test whether the assay itself is performing as expected. These include tests of properties such as goodness-of-fit of reference or QC samples or checks on the relative potency of a QC sample to establish that the assay’s bias is not problematic. If an assay fails on a system suitability criterion, then a repeat of the whole assay is usually required.
Sample suitability criteria
Sample suitability criteria are applied to individual test samples, and are intended to ensure that those samples are behaving as expected. Examples of sample suitability criteria include tests for parallelism or precision criteria on the relative potency estimate. If a sample fails its suitability criteria then only that sample need be repeated: we can regard data from other samples in the same assay which pass sample suitability as valid.
In general, both system and sample suitability criteria are required for all assays. The choice of which criteria are selected for an assay can have a noticeable effect on the assay’s failure rate. We always want to make sure that the assay failure rate is as small as possible, as any assay failure can prove an expensive waste of time and resources. So let’s look at some of the common ways an assay’s failure rate can be unnecessarily increased by poor choices of suitability criteria.
Too Many Suitability Criteria
It can be tempting to pack your assay with a lot of tests: surely more tests means that you’re more confident in your result, right? Unfortunately, more is not always merrier with suitability testing.
Whenever we use a statistical test, there is always a certain probability that the test will fail purely due to chance variability. This is known as the Type I error, and it’s a crucial part of the definition of any test. For example, when we define a significance test as having a significance level of 5%, then we can interpret this as saying that the test will fail by chance 5% of the time, on average.
So, let’s imagine we’re running an assay, and all our suitability criteria are tested using a test with a significance level of 5%. With just one test, we would expect 5 in every 100 assays to fail by chance – this is fairly innocuous. If we add a second test, however, the probability that the assay fails by chance increases to 9.75%, assuming that the results of the tests are independent (more on that later). The chance remains 5% that any individual test fails, but the chance that any test fails increases: we are asking “what are the chances that Test 1 or Test 2 fails?”
So, if we were to use 5 tests, then all of a sudden we have more than a 20% chance of our assay failing purely by chance! And that’s on top of any failures caused by genuine problems with the assay. This is clearly unsustainable. It is, therefore, vital that we do not include more tests than are required to ensure that our assay is behaving correctly.
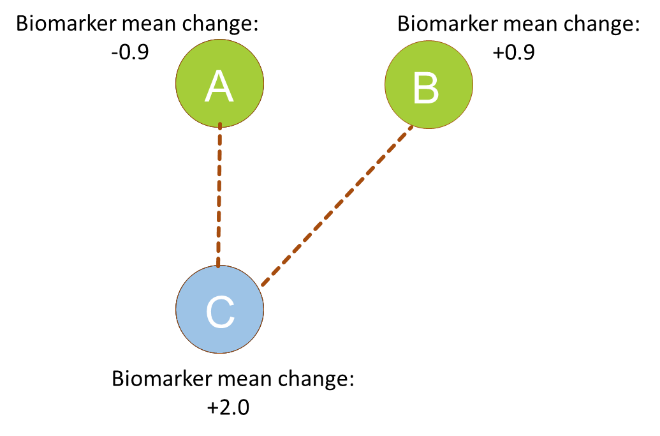
Correlated Suitability Criteria
Another consideration when setting up the suitability criteria for an assay is whether multiple tests are – perhaps unintentionally – measuring the same thing at the same time. We would call these tests correlated, since they would tend to pass and fail the same assays.
An example might be a test for parallelism based on comparing model parameters for the test sample and the reference standard. We’ve discussed parallelism in detail elsewhere, but for a refresher, two 4PL models are considered parallel if all parameters are identical except for the EC50. So, one way to check if the test sample exhibits parallelism is to perform tests comparing some or all of the model parameters of the test sample to the reference to check whether they are considered statistically similar.
Let’s say that you were to set up such tests on the upper and lower asymptotes, but also the assay range, which is the difference between the asymptotes. This would be an example of correlated tests, since the assay range depends on the upper and lower asymptotes by definition. If the range of the test sample is different to that of the reference, then it is almost guaranteed that at least one of the asymptotes is different too, which means both tests are likely to fail at the same time.
In this situation, we might instead consider setting suitability criteria on the assay range and only one of the asymptotes. This means that we are still checking the similarity of the samples with the same stringency as before but using only two tests rather than three, also saving time and resources.
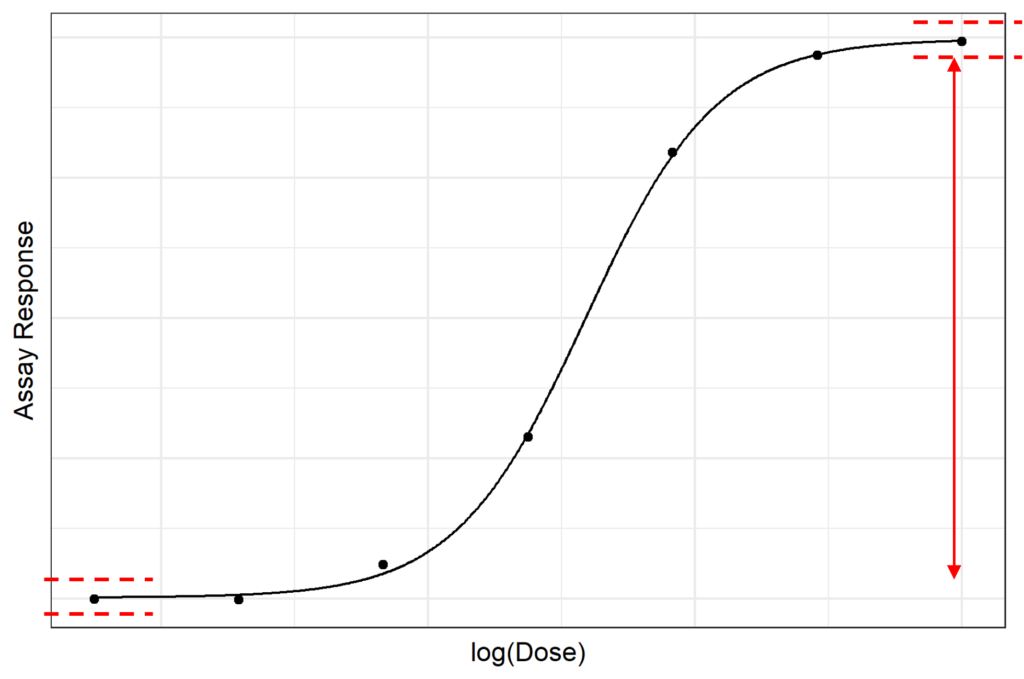
Inappropriate Suitability Criteria
This is probably the most common reason we see unnecessarily elevated failure rates in our clients’ bioassays. If a suitability criterion is set with inappropriate limits, set on a badly chosen parameter or combination of parameters, or checked using the wrong statistical test, then the assay can see massively increased failure rates as a result.
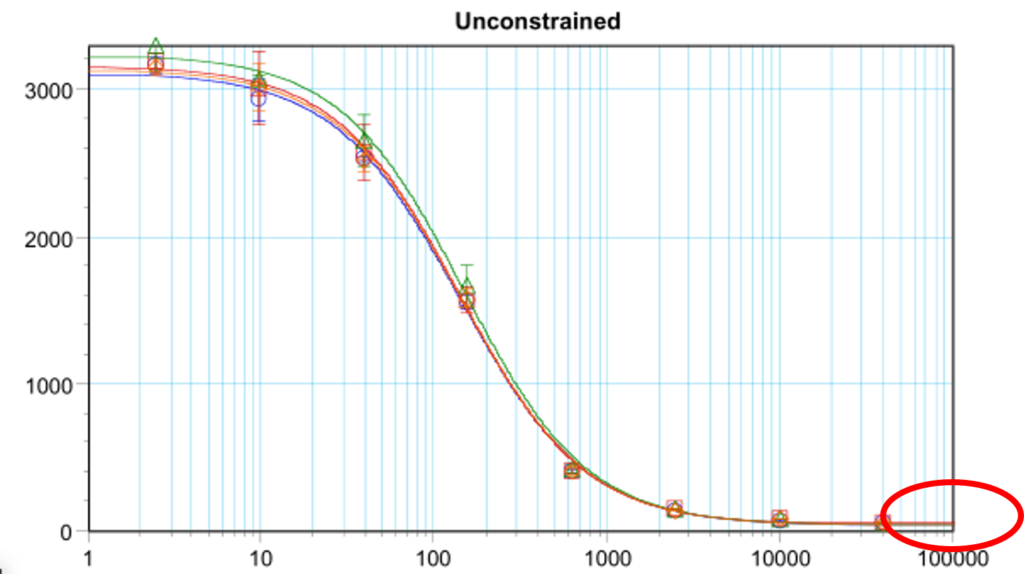
An oft-cited example is the use of the F-test for very precise assays, either for testing system suitability in the form of goodness-of-fit or for sample suitability by testing for parallelism. As we’ve discussed previously, the F-test aims to determine how much of the scatter of data about the fitted model is due to natural variability and how much is as a result of a poor model fit. It does this by comparing the pure error of a dose group (the total distance from each replicate to the mean of the replicates) to the lack-of-fit error (the distance from the mean of the dose group replicates to the model line).
For a very precise assay, the pure error will always be small, meaning that the lack-of-fit error will dominate. This can cause the assay to fail an F-test even if, by any other measure, we would expect it to pass.
What would be an indication that the F-test might be a bad idea for your assay? If you expect that your assay will have high precision – such as if you’re using robotics to plate your assays – then it might be better to stay away from the F-test. Another case would be if you were using pseudo-replication, which reduces the variability of replicates due to correlations. In a simulation study, we showed that strongly correlated replicates exhibit up to a 99% failure rate on an F-test for goodness-of-fit, meaning this test is a particularly poor choice in this case.
If you have sufficient historical data, then using an equivalence test instead of a significance test such as the F-test is a good option. While this is statistically more involved to set up, it circumvents the precision issues which surround the F-test. Alternatively, a test of the “next model up” can be a solution for assessing the suitability of the model when historical data is not available for an assay. If you’re using a 4PL model, for example, you could fit a 5PL model to the data and test whether the E parameter was statistically different from 1. If it is, this would be evidence that a 5PL gives a better model fit than a 4PL for that data. If we’re expecting our data to fit a 4PL, then this could be an indication that something has gone wrong.
A further example of suitability criteria which can often prove inappropriate are those based on the ratio of model parameters, which are often used to test for parallelism. If the ratio of chosen parameters is close to 1, then this is evidence of similarity between the reference and test sample. If, however, one of the parameters is typically close to zero, this can be problematic as dividing by a small number can give a result which is much larger than 1, even if the difference between the model parameters is small.
A common case when this problem arises is if an assay’s response at low dose is close to zero. If a suitability criterion based on the ratio of the lower asymptote parameter is chosen, then it is likely that we would see unnecessary assay failures due to the ratio of parameters. We typically recommend, therefore, that the difference between parameters is used instead of the ratio, as this does not have the same tendency to blow up as does a parameter ratio. So, testing parameter differences rather than ratios is a good way to avoid unnecessary assay failures.
Finding an Optimal Solution
Bioassays are complex experiments which require significant resources, both in terms of personnel and hard cash, to develop and run effectively. No two will ever be the same, meaning the best solution for one assay might cause endless strife for the next. Nevertheless, we hope that the recommendations we’ve pointed out here will inspire thought towards optimising your assay design through considered choices around your suitability criteria. And, if you need any further guidance, Quantics is always here to help!