R We Nearly Squared Yet? Why R² is a Poor Metric for Goodness-of-Fit
One of the most important metrics when analysing bioassay data is goodness-of-fit — how well does a dataset fit a chosen model? In development, this question can help determine which model is appropriate for a dataset, while new data will have to meet a goodness-of-fit criteria to ensure it is adequately represented by the chosen model to pass GMP requirements in routine analysis. What do we use to determine goodness-of-fit? We often see our clients using the coefficient of determination — more commonly known as R² — as a metric for goodness-of-fit for both linear and non-linear models. When asked at BEBPA Europe 2021, 35% of respondents told us they use R2 for this purpose even for non-linear dose response models, such as a 4PL. Indeed, this is not a fluke. SoftMax Pro for bioassay analysis claims “The R2 value is generally a good representation of the goodness-of-fit”.
All good then? Not so fast. In their 2010 paper, Spiess and Neumeyer beg to differ, stating “Researchers and reviewers should be aware that R2 is inappropriate when used for demonstrating the performance or validity of a certain non-linear model”. Even SoftMax Pro can’t make its mind up, admitting — in the same blog post, no less — that “R2 can be a poor measure of curve fit quality”.
Key Takeaways
- R2 measures how much of the total variation in the response is “explained” by a model, but it only looks at variation around the mean or fitted curve — not whether the model actually matches the shape of the data.
- A low R2 does not always signal a bad fit: if the total variability in the data is small, even a visually excellent fit can yield a modest R2 value.
- A high R2 can hide systematic misfits, such as regions where the model consistently over- or under-predicts, so using R2 alone as a goodness-of-fit criterion risks both rejecting good models and accepting poor ones.
There appears, therefore, to be some confusion on the question of whether R2 is an appropriate measure of goodness-of-fit. From the title of this blog, you may have guessed where we at Quantics fall on the issue. We want to demonstrate why we think R2 is a poor measure of goodness-of-fit regardless of model form: that a low R2 doesn’t always indicate a poor fit, that a high R2 doesn’t always indicate a good fit, and that R2 doesn’t measure the shape of a dataset in the first place.
What is R2
To examine why R2 is a poor goodness-of-fit measure, we should first understand what R2 is. In short, it is a measure of the strength of the relationship between a dependant variable (typically plotted on the y-axis) and an independent variable (usually on the x-axis). We’ll consider R2 in terms of the variation of the y-value of data points. These are the vertical distances of the data points from a point of interest, such as the mean y-value of the data set or a fitted model curve.
A common formula for R2 is:
\[R^2=1-\frac{SS_R}{SS_T}\]
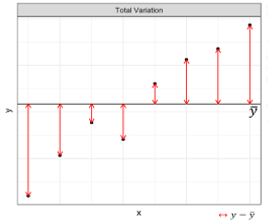
Let’s break this down. \(SS_T\) is the total variation of a dataset relative to its mean. As shown in Figure 1, this is equivalent to asking how close the y-values of each data point are to the mean y-value of the whole dataset. This value will be the same no matter what model we choose to fit to the data—it is model independent—since this variation is a property of the data itself, not of a model we impose.
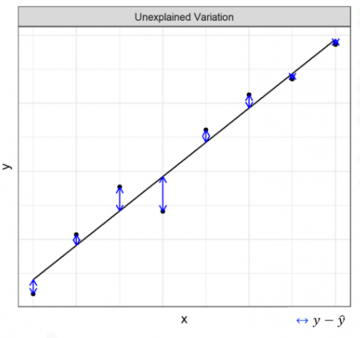
Conversely, residual variation, \(SS_R\), does depend on our choice of model. Specifically, it measures the vertical distance of the points from the curve we fit to the dataset, which is shown in Figure 2. It is, in a sense, the variation which is “left over” when we fit a model to our dataset: that which is not “explained” by our choice of curve. And, since the distance between the points and the curve will change if the curve is changed—it is model dependent—the residual variation changes depending on which model we choose to fit.
R2 takes the ratio of these two variations, and subtracts it from one. If we choose a model whose curve passes each data point exactly, there will be no residual variation (\(SS_R = 0\)), meaning R2 = 1. Conversely, if we choose the mean of the data as our model, then the residual variation will be identical to the total variation (\(SS_R=SS_T\)), and R2 = 0.
So, what does R2 actually tell us? Recall our original definition of R2: a measure of the strength of the relationship between a dependant and independent variable. If the relationship between the variables is strong, most of the variation in the data is explained by a best-fit model we impose, and R2 is close to one. If the relationship is weak, however, then most of the variation is random noise in the data, meaning the residual variation will be large when we impose our model. This would result in a low R2.
Low R2 doesn’t always mean a bad fit
From our investigation so far, it’s easy to see why R2 could be confused with a measurement of goodness-of-fit. One would expect a well-fitted model to explain most of the variation in a dataset, after all, and this is integral to the value of R2. However, the connection does not hold in all cases. Far from it.
Take the two datasets shown in Figure 3. It is (hopefully) clear that these datasets are well-fit by the same linear model, which we can see in Figure 4. If R2 was a measure of goodness-of-fit, we might expect these two models to have similar R2 values.
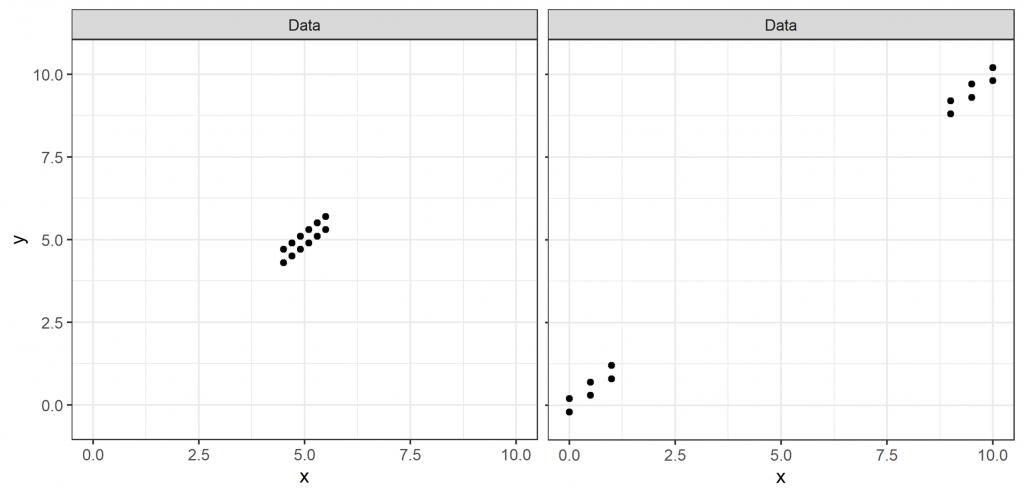
But do they? While the data in both sets lie close to the fitted curve, meaning that the residual variation (\(SS_R\)) is small, the data in the left-hand plot is much closer to the mean (here = 5) than in the right-hand plot. This means that the total variation (\(SS_T\)) for the plot on the left is much smaller, and, therefore, the ratio \(\frac{SS_R}{SS_T}\) is much greater. This results in an R2 of 0.74 for the left-hand plot, while the R2 of the right-hand plot—whose data lies further from the mean, resulting in a larger \(SS_T\)—is close to one.
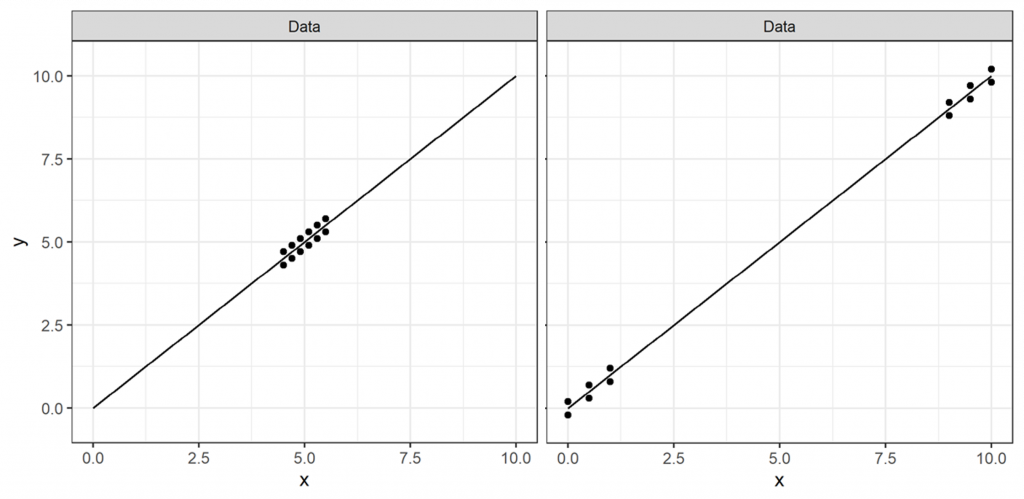
See the problem? Using R2 as a goodness-of-fit measure, we’d surely reject the left-hand model with an R2 as low as 0.74. But we can visually see that the model we’ve used fits the data very well, in fact near-equally well as the right-hand plot with an R2 of close to one. While this is a single, constructed, example, it definitely shows that a low R2 does not always indicate a poor model fit.
High R2 doesn’t always mean a good model fit
So, we know that R2 is not a good measure of model fit at the lower end, but maybe a high R2 is still a sign of a good model fit? The right-hand plot in Figure 4 has a R2 close to one, after all, and we can visually see that’s a very good model fit. Sadly, even here, things are not that simple.
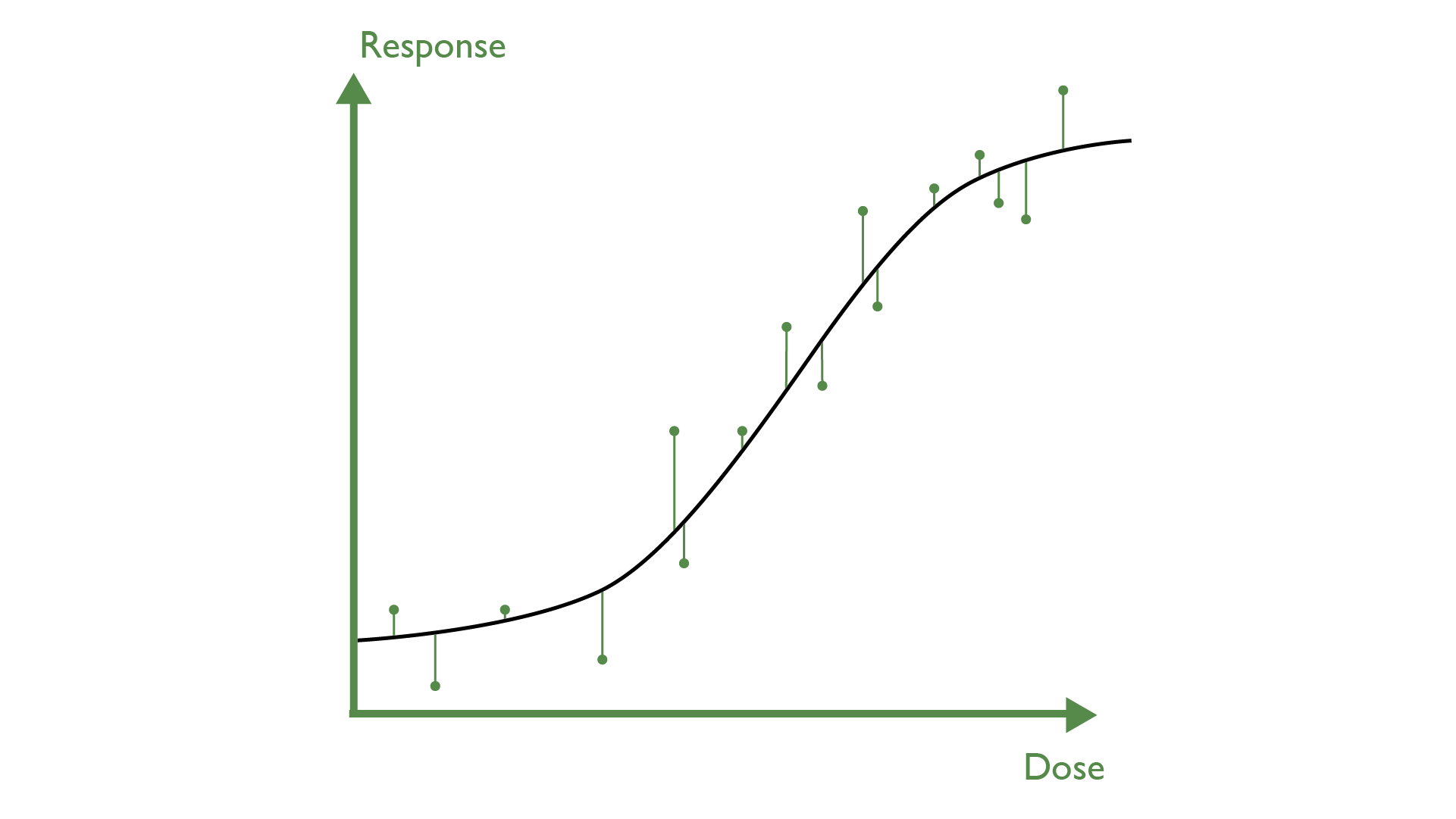
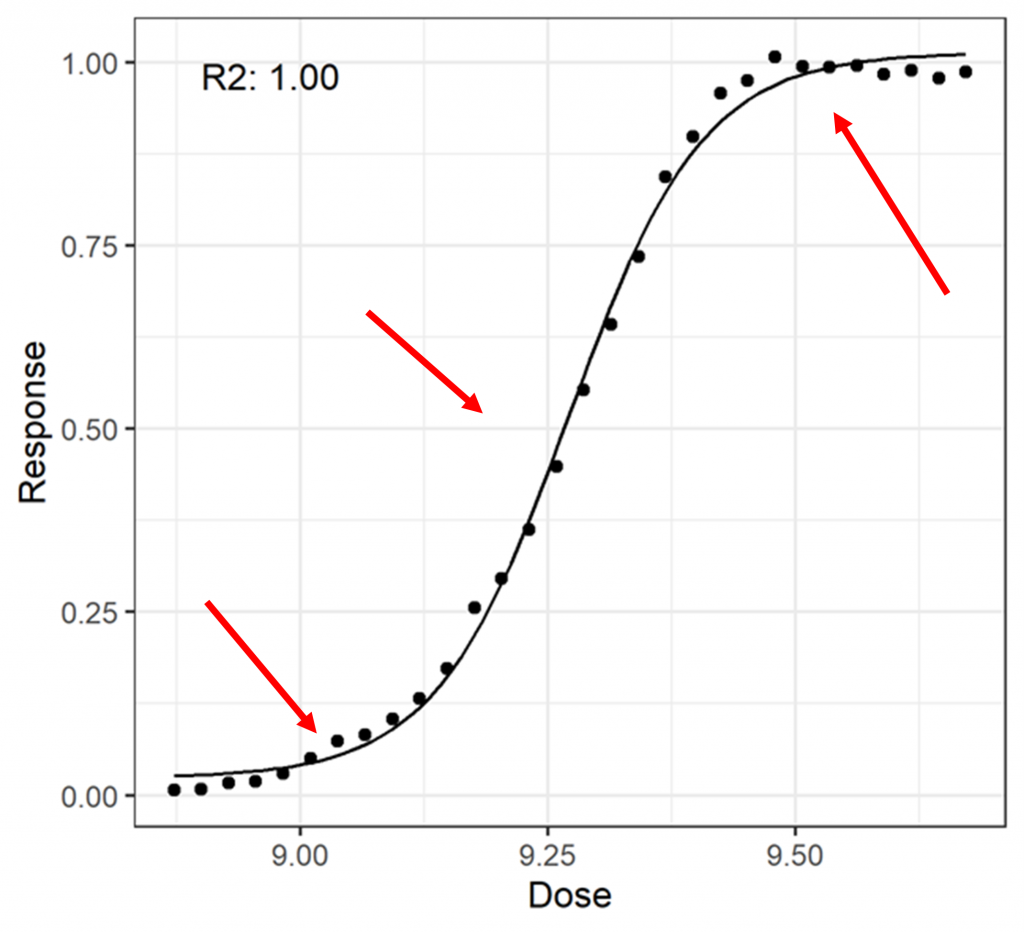
In Figure 5, a more complex dataset has been fit with a 4PL model. The datapoints are pretty close to the curve throughout, which means that \(SS_R\) will be small compared to \(SS_T\). This results in a R2 of close to one.
Again, we can see there’s a problem here. There are regions—indicated by red arrows—where the model is systematically a poor fit for the data. That is, the curve passes over or under several consecutive datapoints. For a good model fit, we would expect a more even distribution of points falling above and below the model curve over the full range of the data, as this is the pattern of variation more typically associated with random noise. Since there are systematic model fitting failures, it is easy to make the case that the model is not a good fit for the data despite the high R2 value. Once again, then, we find that the R2 value is not a good representation of the goodness-of-fit of the model.
Why is R2 not a measure of goodness-of-fit?
A high R2, then, tells us similarly little about the goodness-of-fit of a model as a low R2. This leaves just one question outstanding: why? R2 is a measure of how well a model explains the variation of a dataset so, intuitively, we might expect that it would measure goodness-of-fit.
The issue is that the variation is not the only important factor in goodness of fit: the shape of the data is also relevant. R2 takes this information about the shape of the data—in the total variation \(SS_T\)—and amalgamates it with information about the variation of the data around the chosen model—the residual variation \(SS_R\). This combination is awkward to separate, and means that R2 does not answer the all-important question of whether the shape of a dataset is matched well with that of a chosen model.
While R2 may intuitively seem like a simple way to measure the goodness-of-fit of a model, it is not the appropriate tool for the job. It is true that many well-fit models have a high R2 value, while many a poorly fit model will have a low R2, but this is coincidence. R2 does not measure the shape of a dataset, which is the most important factor when determining goodness of fit. It is easy to concoct well-fitted models with low R2 values, as well as poorly fitted models with a high R2. To use R2 as a metric for goodness-of-fit, therefore, is to not only risk unnecessary failures of perfectly good datasets, but also—and more concerningly—flawed datasets slipping through the cracks.
We hope that this blog has helped you to understand the problems of R2. Choosing the best suitability criteria for your assay is not simple, and it is easy to end up with criteria that fail to perform as you expect, particularly when used in combination. Quantics is always happy to discuss system and sample suitability criteria choice, and this can usually be achieved with an analysis of development data. Doing this before it is all set in stone in commercial is a good idea!