
Hidden Consequences of Interim Analyses & Adaptive Trial Options
Interim analyses are common in medical device trials for a variety of reasons. Just having a look is fine, but if the outcome of the analysis could change the conduct of the trial, for example by early stopping for superiority, futility or safety, then there is a problem. If the analysis result does stop the trial, then all is well, but if the analysis does not show that the trial can be stopped early, then the fact of having undertaken the analysis might undermine the power of the trial to demonstrate the objective when the trial is finally complete.
To understand this let’s start by reviewing statistical testing. Consider a trial where we hope the new treatment is better than the old.
Reviewing statistical testing
Key Takeaways
- Interim analyses that can change trial conduct (e.g. early stopping for superiority, futility or safety) will inflate the overall Type I error rate unless they are prospectively planned and adjusted for.
- Standard hypothesis testing assumes a single analysis at the end of the trial; adding extra “looks” without alpha control can almost double the chance of a false positive conclusion.
- Plans for interim analyses, including their purpose and statistical handling, must be defined before the trial starts in line with guidance such as ICH E9.
The standard statistical process is:
- State the objective of the test, which is to show either:
- Specify the significance level – typically 5%.
- Compute the test statistic and p-value (the detailed discussion is beyond this blog).
- Compare the p-value to the significance level to make a decision.
For step 1, we define two hypotheses:
- The new treatment is the same or worse than the current treatment/placebo – called the null hypothesis.
- The new treatment is better than (superior to) the current treatment/placebo – called the alternative hypothesis.
If p-value ≤ significance level → reject the null hypothesis; conclude the alternative i.e. that the new treatment is better ✓
If p-value > significance level → fail to reject the null hypothesis; we cannot show that the new treatment is better – it might be better, or worse, or just the same X
So far so good. Of course, the decision is based on a sample and could be wrong in either direction:

This example used efficacy as the primary measurement, but the same applies to safety.
It is the Type 1 error that has to be avoided from a safety and regulatory point of view. Type 2 errors are just wasted opportunity for the device.
So let’s consider the case where the null hypothesis is actually correct – the new treatment/device is no better, or is worse than the comparator. At each analysis point there is a 5% chance of a false conclusion, and therefore a 95% chance of a correct conclusion.
Design 1) Straightforward design without interim analysis
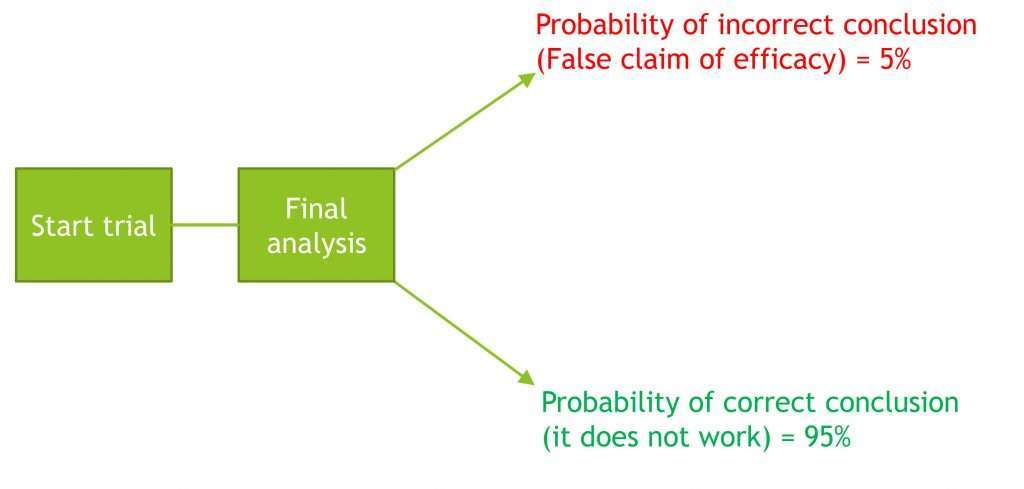
Overall, there is a 5% chance of a false claim of efficacy. This is acceptable.
But now let us add an interim analysis.
Design 2) Design with added interim analysis
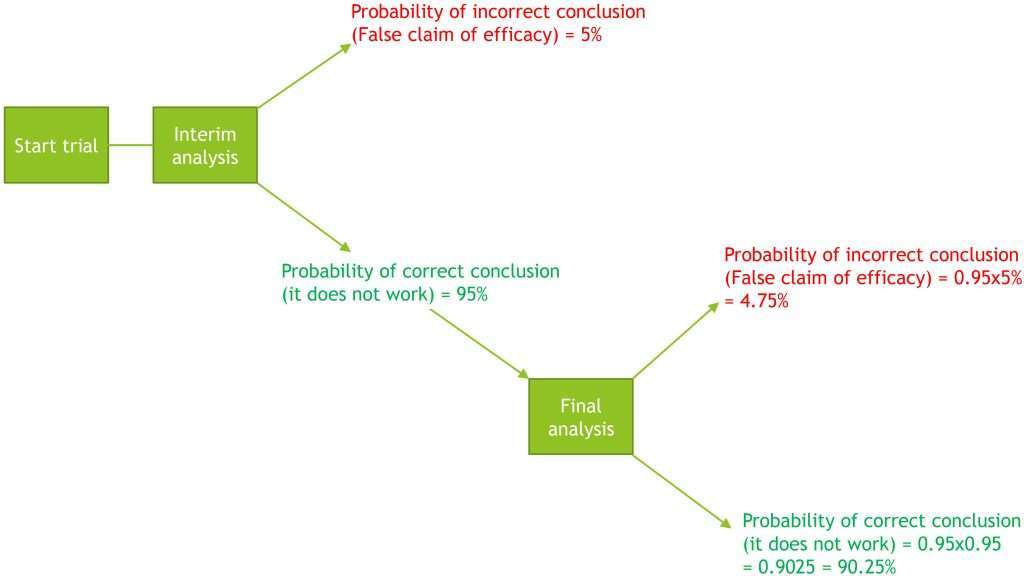
Overall probability of the trial incorrectly concluding efficacy = 5% + 4.75% = 9.75%
Overall probability of the trial making a correct claim of efficacy = 90.25%
If the study continued to the planned end and claimed efficacy, the regulators would say that there was a 9.75% chance that this was a false claim, and would reject the trial conclusion.
Accommodating interim analyses and alpha spending
So how can an interim analysis be accommodated?
The whole study must have a maximum 5% chance of a false claim of efficacy, but this 5% can be shared between the interim analysis (or analyses) and the final analysis. This is called alpha spending.
The maths now gets more complex as there are different ways to “spend the alpha”. This is a balance between the chance and benefits of an early stop versus the increase in sample size required to keep the overall chance of a false claim of efficacy to 5%, if an early stop is not supported. The two common “alpha spending functions” are:
- O’Brien–Fleming boundaries
- Pocock boundaries
In general O’Brien–Fleming boundaries spend a small amount of alpha and will therefore minimise the potential increase in sample size, but also minimise the chance of an early stop. In the context of your trial, if it is expensive or difficult to recruit and treat more patients, and the benefit of the treatment is relatively small, then this might be a good choice.
Pocock boundaries will provide a reasonable chance of an early stop by spending more alpha, but this is done at the risk of a substantial increase in sample size if an early stop is not achieved. This might be a better choice if recruitment is easy and cheap, or you are reasonably confident that the new treatment is much better than the old, in which case an early stop is both likely and beneficial.
How much alpha is spent at the interim also depends on when the interim is done. The more data available, the greater the alpha spending for a given alpha spending function. This is illustrated in Figure 1, which shows how the alpha spending for the two spending functions varies depending on what percentage of the planned number of patients are part of the interim analysis.

Figure 1 Alpha spending as a function of timing of interim analysis
Figure 2 illustrates the change in sample size required to maintain an overall 5% risk of false positives in the event that the trial continues after an interim analysis, as a function of timing and alpha spending function.
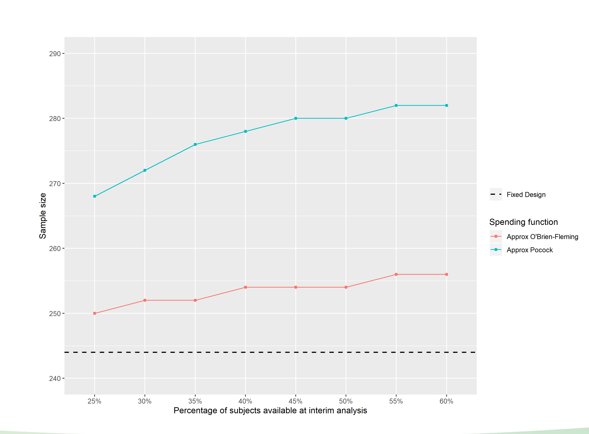
Figure 2 The change in sample size required to maintain an overall 5% risk of false positives
Generally, statisticians can provide a number of different scenarios for this three-way balancing act that the study design team can use to make a decision.
Summary
If an interim is planned, it is vital to define what it is for. If it is just for information and the trial will continue as planned whatever the result, then there is no problem (although knowledge of the interim result at investigator level could lead to bias).
On the other hand, if there is a chance that the interim analyses could change the trial progress, this must be carefully planned BEFORE THE TRIAL STARTS, so that the integrity of the trial is not put at risk in the event of the interim analysis being inconclusive. More information about interim planning can be found in ICH E9 (Statistical Principles for Clinical Trials), section 4.5.






