
How to Build a Confidence Interval
In parts 1 & 2 of our series on the confidence interval, we have covered some of the basic statistical concepts – means, standard deviations, and distributions – and how they can be used to describe the results obtained from a bioassay. Then, we described how we can investigate the distribution of our sample-based estimates using the standard error and the central limit theorem.
Here, we’re going to use the ideas we’ve discussed previously to, at last, fully define the confidence interval, describe the process of constructing one, and investigate it’s meaning.
Let’s return once again to the measurement we’ve been using throughout this series: the EC50 of a lot. Recall once again that we’re treating the EC50 as measured on the log scale, since then we can safely assume that the values we observe are drawn from a normal distribution. In part 2, we examined the following dataset:
Key Takeaways
- A confidence interval summarises uncertainty in an estimate, such as an EC50, by giving a range of plausible values rather than a single point, making interpretation more informative than quoting the mean alone.
- The width of a confidence interval depends mainly on the standard error and the chosen confidence level: more data narrows the interval, while demanding higher confidence (for example 99% instead of 95%) widens it.
- In bioassay, confidence intervals underpin both significance testing (detecting differences from benchmarks) and equivalence testing (showing results are within acceptable limits), so they are central to many assay suitability decisions.
The Ingredients
|
Sample No |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
EC50 (x) |
3.03 |
2.81 |
4.16 |
2.99 |
2.91 |
3.44 |
4.07 |
3.31 |
3.22 |
2.46 |
|
Sample No |
11 |
12 |
13 |
14 |
15 |
16 |
17 |
18 |
19 |
20 |
|
EC50 (x) |
2.77 |
3.29 |
2.13 |
3.76 |
2.69 |
3.32 |
3.79 |
2.79 |
3.2 |
2.57 |
|
Sample No |
21 |
22 |
23 |
24 |
25 |
26 |
27 |
28 |
29 |
30 |
|
EC50 (x) |
3.59 |
3.32 |
3.14 |
3.14 |
1.84 |
2.92 |
3.33 |
4.08 |
3.29 |
3.09 |
And determined that it had the following properties:
Sample Mean: \(\bar{x}=3.15\)
Sample Standard Deviation: \(s_x=0.53\)
Standard error: \(s_{\bar{x}}=0.1\)
Now, we want to construct a confidence interval for the population mean. What do we need?
Well, we already have two ingredients to hand: the sample mean, \(\bar{x}\), which informs the centre of the confidence interval, and the standard error, \(s_{\bar{x}}\), whose purpose will become clear in a moment.
For the final component, we need a reference value from a distribution. Since we only have an estimate for the population standard deviation, we would typically need to use a t-distribution. In this case, however, our sample size is large enough that we can approximate the t-value from the standard normal distribution, which we will do for the sake of simplicity. Our reference value is, therefore, a Z-score and is denoted by z*.
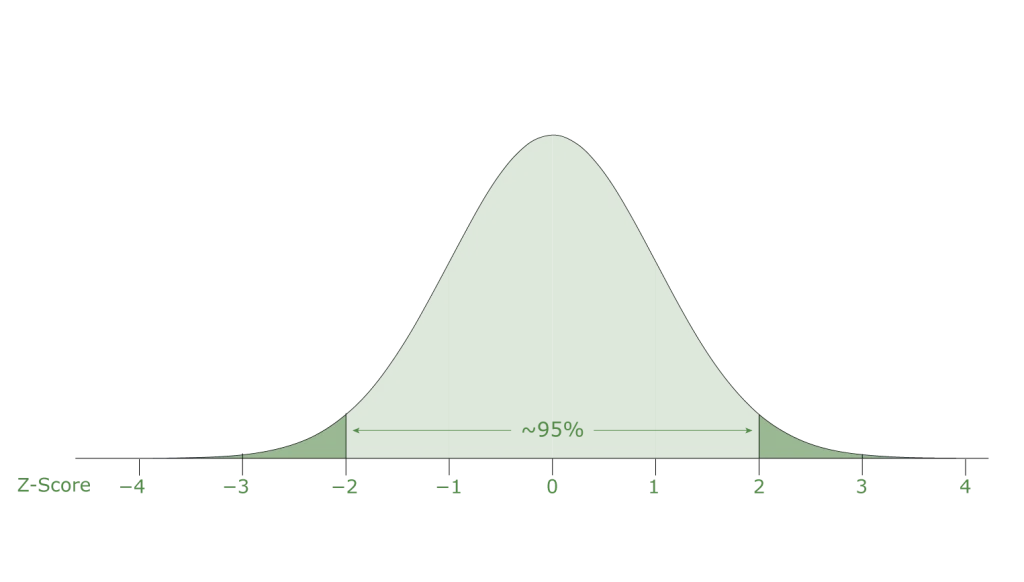
We then use a handy feature of normal distributions. For any normally distributed population, we can calculate the percentage of observations we would expect to see at set distances away from the mean. We measure these distances in terms of the standard deviation of the distribution. For example, about 67% of the data falls within 1 standard deviation of the mean, about 95% of data falls within 2 standard deviations, for any normal distribution.
Let’s say that our desired confidence level is 95%. The Z-score for our confidence interval then tells us the size – in standard deviations – of the window we need to cover 95% of the distribution. In this case we will need z*=1.96 to construct a 95% confidence interval.
The Recipe
With our ingredients gathered, let’s cook. The formula which determines the upper confidence limit (UCL) and lower confidence limit (LCL) for our confidence interval is:
\[\left(LCL, UCL\right)=\bar{x}\pm\left(z^{*}\times s_{\bar{x}}\right)\]
The quantity \(\left(z^{*}\times s_{\bar{x}}\right)\) is often referred to as the margin of error.
For our test lot data, we calculated \(\bar{x}=3.15\) and \(s_{\bar{x}}=0.1\). If we wanted to find the 95% confidence interval, the margin of error would be (to 3 significant figures):
\[\left(1.96 \times 0.1\right)=0.196\]
Which means the 95% confidence interval is:
\[\left(LCL, UCL\right)=3.15\pm 0.196 =\left(2.95,3.35\right)\]
We can, therefore, say that we are 95% confident that the “true” EC50 of the sample lies between 2.95 and 3.35 based on the experimental data gathered.
Interpreting a Confidence Interval
So, we now know how to build a confidence interval from sample data. But what does it actually mean? How does it connect the sample data to the “true” value we care about?
The key point is this: the confidence level tells us about the likelihood that the “true” value is contained within the confidence interval with repeated sampling. If we were to repeat our process – measure the EC50 of 30 samples, calculate the relevant properties, and construct a 95% confidence interval – 100 times, then we would expect that (approximately) 95 of those confidence intervals to contain the “true” EC50.
In some senses, the confidence interval tells us more about the estimate of the “true” value in which we’re interested than the point estimate itself. As an analogy, imagine trying to catch a fish in a muddy pond. Considering only the sample mean is like using a fishing line: you’re only looking in one place, so you’re unlikely to catch the fish. Using a net is like reporting a confidence interval, just as you are far more confident that you’ll catch the fish, you’re more likely to include the “true” value within the confidence interval.
What Determines the Width of a Confidence Interval
From the formula, we see that we there are two contributing factors which affect the width of a confidence interval: the standard error, and the Z-score associated with the confidence level.
Since the standard error depends inversely on the sample size, increasing the sample size decreases the width of the confidence interval for a constant confidence level, and vice versa. This seems intuitive: adding more data seems like it should give us a better estimate. This means that the confidence interval will be narrower while still capturing the “true” value 95% of the time (with repeated sampling).
Perhaps less intuitive is the dependence on the confidence level. For example, a confidence interval at a higher confidence level—say 99% instead of 95%—will be wider for the same dataset. This might seem backwards: we’ve just said that a smaller confidence interval is associated with the location of our “true” value.
Let’s return to our fishing analogy. Remember that catching the fish is equivalent to including the “true” value in the confidence interval. How could you increase your confidence of catching a fish? Use a bigger net! Increasing the confidence level of your interval is exactly the same: a wider interval is more likely to include the “true” value, so increasing the confidence level results in the confidence interval growing in size.
Confidence Intervals in Bioassay
So how do we use confidence intervals in bioassay? A typical interpretation is to say that the confidence interval represents a range of plausible values for the parameter in question.
One way this is used is to check the suitability of an assay. For example, we may wish to compare the EC50 of the new test lot from our example to that of a historical benchmark. If our historical benchmark EC50 is, say, 3.5, it falls outside of our sample confidence interval of (2.95, 3.35).
This is exactly equivalent to performing a two-sided significance test at a significance level of 0.05 (0.025 at each end). So, we can say that our new value is significantly different from the historical benchmark, which is an indication that there may have been a problem with the assay. That’s because we have evidence that the difference between the result from our experiment and the historical benchmark is unlikely to be due to the normal variability of the assay.
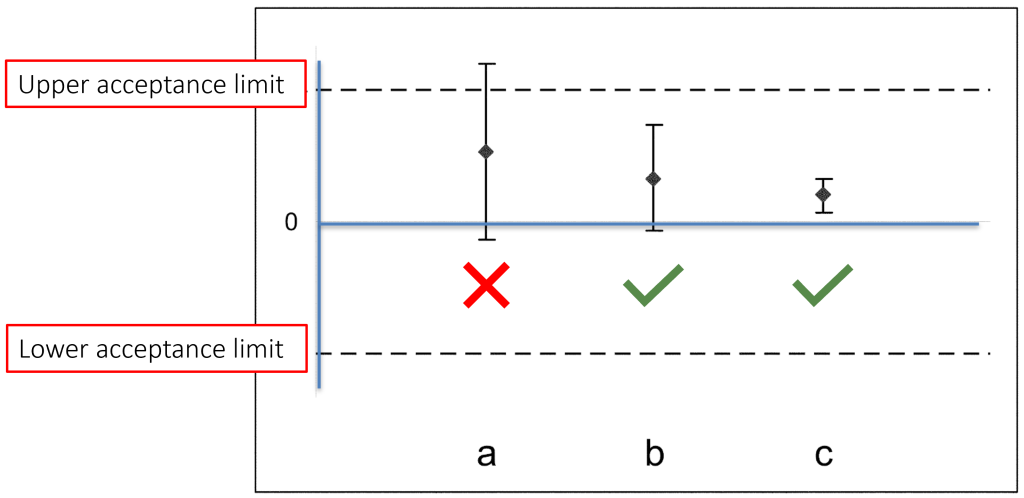
An alternative approach to testing suitability of assays is equivalence testing, where the test EC50 is considered equivalent to the historical EC50 if the entire confidence interval falls within pre-defined equivalence limits. Let’s say we determined these equivalence limits for the historical benchmark to be (2.9, 3.5). Since our confidence interval falls entirely inside this range, then our new lot is considered equivalent to the historical benchmark, and we have evidence that our assay has performed as expected.
So, what is a confidence interval?
Confidence intervals are often thought as like error bars: simply a representation of the uncertainty of a measurement. While variability is certainly taken into account, a confidence interval tells us far more than that. It is a way of encapsulating the relationship between experiment and reality, which, after all, is at the heart of statistics.
As well as a powerful theoretical tool, confidence intervals are among the most vital components when performing statistical inference in the world of bioassay. When interpreted as a range of plausible values, they can be used in a similar way as significance tests, or in a more sophisticated equivalence test. Either way, confidence intervals are one of the most important tools in a statistician’s toolkit.







