
The key assumptions of network meta-analysis
Like all statistical analyses, network meta-analysis relies on a specific set of assumptions. Here, we’ll look at the key assumptions of network meta-analysis. In order to draw valid conclusions about the relative efficacy and safety of treatments in a network meta-analysis and facilitate good decision making, it is important to understand and evaluate these assumptions.
Network meta-analysis is an extension of ordinary pairwise meta-analysis, and so the assumptions are very similar. The validity of both meta-analyses and network meta-analyses depends on:
- the adequacy of the evidence base, and
- the similarity of the trials.
Adequacy of the evidence base
Key Takeaways
- A valid network meta-analysis relies on a comprehensive and unbiased systematic review, including high-quality studies with minimal risk of bias and sufficient transparency to assess factors like randomisation, blinding, and missing data handling.
- The assumption of similarity requires that studies included in the network do not differ in key design or patient characteristics that may modify treatment effects; otherwise, indirect comparisons may be invalid.
- NMA validity depends on homogeneity (consistency within direct comparisons), transitivity (validity of indirect comparisons via common comparators), and consistency (agreement between direct and indirect evidence), all of which must be critically assessed through both qualitative and quantitative methods.
The adequacy of the evidence base depends on both internal and external factors. Internally, when developing a network meta-analysis, a systematic review should be used to identify relevant studies. Using a systematic approach helps ensure there is no bias in study selection.
Guidelines for health technology assessment submissions and network meta-analysis publications (for example, the NICE Guide to the Methods of Technology Appraisal and the PRISMA extension statement for network meta-analysis) require that network meta-analyses are based on a systematic review.
Externally, adequacy depends on the quality of the relevant studies and whether they have been fully published. Meta-analysis and network meta-analysis are only as good as the studies they include. Key considerations include how patients were randomized, whether patients and outcome assessors were blinded, and how missing data were handled.
The Cochrane risk of bias tool is commonly used to assess study quality. If some studies have a high risk of bias, sensitivity analyses with and without these studies are recommended.
Publication bias is also a major concern. Positive results may be more likely to be published than negative results. Publication bias can occur at the study level (entire studies unpublished) or outcome level (results partially published). Methods such as funnel plots can be applied to pairwise comparisons within a network when there is sufficient data. Methods for assessing publication bias across entire networks have also been proposed.
Similarity of the trials
In both meta-analysis and network meta-analysis it is important to consider the similarity of the trials. The key assumption is that trials should not differ in any characteristics that may impact the treatment effect.
It is important to distinguish between treatment responses (how patients respond to an individual treatment) and treatment effects (the difference in response between two treatments). To illustrate, consider a trial comparing two treatments for tiredness: tea and coffee.
Figure 1: Treatment responses and treatment effects.
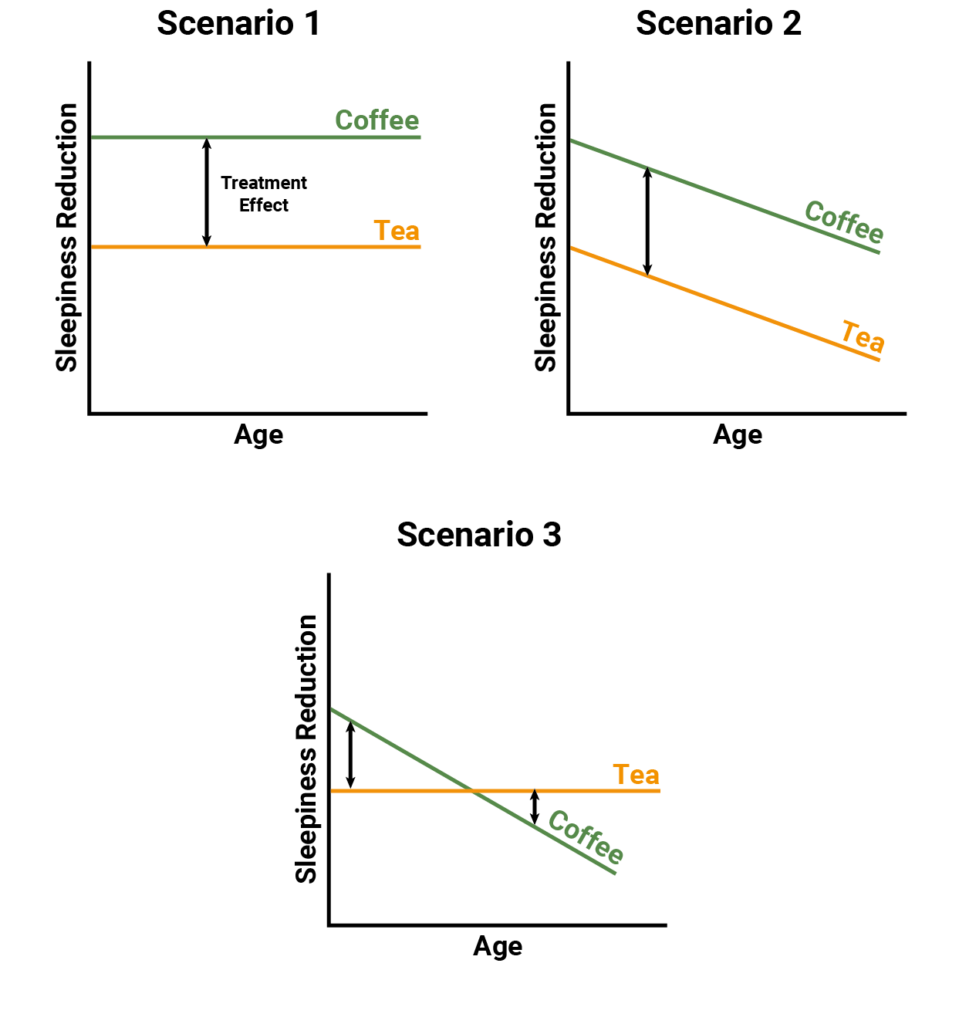
Figure 1 illustrates three scenarios for the relationship between the treatments (tea and coffee), the outcome (reduction in tiredness) and age. In Scenario 1, age doesn’t affect treatment response for either tea or coffee, and so it does not affect the treatment effect. In Scenario 2, age reduces response to both tea and coffee in the same way, so the treatment effect is still constant. In Scenario 3, age reduces response to both treatments, but has a greater impact on coffee, so the treatment effect depends on age.
For Scenarios 1 and 2, age is not a treatment effect modifier and it would be appropriate to combine studies of younger and older patients. For Scenario 3, age modifies the treatment effect and it would not be appropriate to combine studies across very different age groups without adjustment (for example via meta-regression).
Both study design characteristics and patient characteristics can modify treatment effects. In the tiredness example, design characteristics might include trial setting, formulation of treatment (instant coffee versus espresso), and the timing of outcome measurement. Patient characteristics might include concomitant medications and severity of tiredness.
In network meta-analysis, we want all trials in the network to be similar with respect to any characteristics that could modify treatment effects. This assumption can be unpacked into homogeneity, transitivity and consistency.
Homogeneity refers to the similarity of trials within each pairwise comparison in the network. It can be assessed qualitatively (by reviewing trial characteristics) and quantitatively (by comparing treatment effect estimates). The I-squared statistic is commonly used to quantify heterogeneity within a direct comparison.
Transitivity (sometimes referred to as similarity) concerns whether indirect comparisons are valid. This cannot be assessed quantitatively and must be evaluated by carefully reviewing whether trials are comparable in effect-modifying characteristics. In the tiredness example, an important question is whether decaf coffee can be considered equivalent to decaf tea as a common comparator.
Consistency refers to agreement between direct and indirect evidence. Like heterogeneity, it can be assessed qualitatively and quantitatively. In simple cases, direct and indirect estimates can be compared. In more complex networks, approaches such as node-splitting can be used.
This brings us to the end of our overview. To support valid inference and good decision making, a network meta-analysis must be based on an adequate evidence base and the trials must be sufficiently similar with respect to treatment effect modifiers.
Further information
If there are any particular topics you’d like to see covered in the future then please let us know. If you are looking for an in depth intro to network meta-analysis, YHEC and Quantics run joint courses – currently available in-house, on request. Some slides from one session of this course are available here.
References
- National Institute for Health and Care Excellence. Guide to the methods of technology appraisal. 2013.
- Hutton B et al. The PRISMA Extension Statement for Reporting of Systematic Reviews Incorporating Network Meta-analyses of Health Care Interventions: Checklist and Explanations. Annals of Internal Medicine. 2015; 162: 777–784.
- Higgins JP et al. The Cochrane Collaboration’s tool for assessing risk of bias in randomised trials. BMJ. 2011;343:d5928.
- Egger M et al. Bias in meta-analysis detected by a simple, graphical test. BMJ. 1997;315:629–634.
- Mavridis D et al. A selection model for accounting for publication bias in a full network meta-analysis. Statistics in Medicine. 2014;33(30):5399–5412.
- Trinquart L et al. A test for reporting bias in trial networks: simulation and case studies. BMC Medical Research Methodology. 2014;14:112.
- Higgins J et al. Measuring inconsistency in meta-analyses. BMJ. 2003;327:557–559.
- Dias S et al. Checking consistency in mixed treatment comparison meta-analysis. Statistics in Medicine. 2010;29(7–8):932–944.
- Salanti G. Indirect and mixed-treatment comparison, network, or multiple-treatments meta-analysis: many names, many benefits, many concerns for the next generation evidence synthesis tool. Res Synth Methods. 2012;3:80–97.






