An introduction to network meta-analysis (mixed treatment comparison / indirect treatment comparison)
Find out about our network meta analysis services
Welcome to Quantics’ health technology assessment blog. This blog will explore some of the statistical aspects of health technology assessment, including meta-analysis, network meta-analysis and survival analysis. The aims of this blog are two-fold. Firstly, we want to create a knowledge base to help those who are new to the area develop a foundation and feel more confident. Secondly, we want to provide thought provoking articles on some of the latest statistical developments in health technology assessment.
The statistical methodologies used in health technology assessment are becoming increasingly complex but Quantics has a rich history of translating statistics into a language that everybody can digest.
Key Takeaways
- Network meta-analysis extends pairwise meta-analysis to compare multiple treatments simultaneously.
- Connected networks are required for standard NMA; disconnected networks need alternative approaches.
- Key concepts include indirect vs mixed treatment comparisons and the assumptions that support valid inference.
In these first posts we will provide an introduction to network meta-analysis. We will outline the key assumptions behind this method and provide some insights into how to effectively plan a network meta-analysis project. In later posts, we will examine some of the more advanced aspects of network meta-analysis such as how to handle disconnected networks and report back on key health technology assessment conferences such as ISPOR. For now, let’s start by looking at the basics of network meta-analysis.
What is network meta-analysis?
To begin with, we will assume that most of our readers are familiar with systematic review and standard pairwise meta-analysis. For any readers who are new to these topics, the Cochrane Handbook provides an excellent guide. A standard pairwise meta-analysis can compare the efficacy or safety of exactly two treatments that have been directly compared in head-to-head clinical trials. However, in practice, there are often many potential treatments for a single disease. Policy-makers, physicians and patients need to be able to select the best treatment from amongst the many potential options. Network meta-analysis is an extension of standard pairwise meta-analysis that can be used to simultaneously compare any number of treatments.
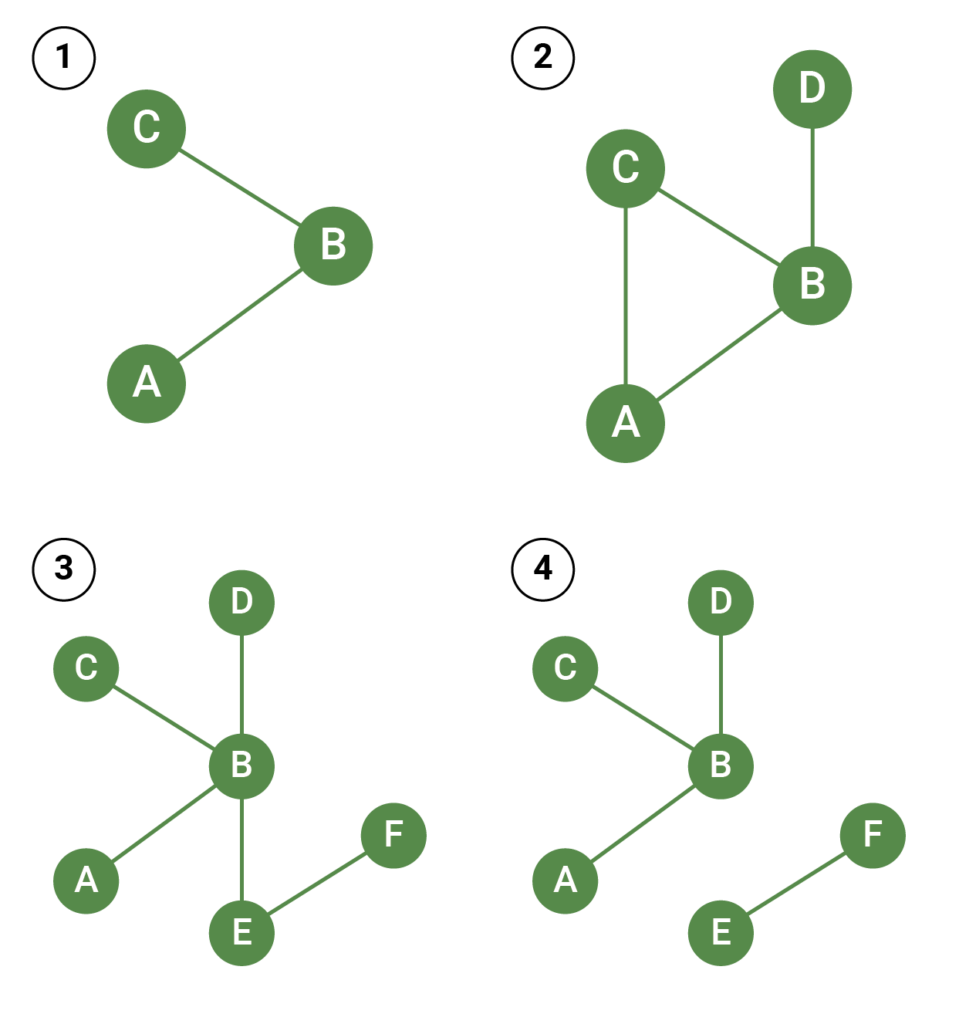
In the simplest possible example of a network meta-analysis, there are two treatments of interest that have been directly compared to a common comparator, but not to each other. Usually the common comparator will be placebo or a standard treatment. This situation is illustrated by Figure 1A. The circles indicate treatments and the lines connect treatments that have been directly compared in head-to-head clinical trials. In this example, treatments A and C have both been directly compared to treatment B, but there are no trials that compare treatments A and C.
There is no limit to the number of treatments, trials and patients that can be included in a network meta-analysis. However, in order to conduct a standard network meta-analysis, the treatments should form a connected network, such that there is a path from each treatment to every other treatment in the network. In Figure 1, diagrams A, B and C all illustrate connected networks. However, diagram D illustrates a disconnected network – there are no trials that connect treatments E and F to the rest of the network. We will look at how to handle disconnected networks in a future blog post.
Standard terminology
You may be familiar with other network meta-analysis terms, such as indirect treatment comparison and mixed treatment comparison. Different groups have used these terms in different ways, but, in this blog, we will follow the definitions proposed by the International Society for Pharmacoeconomics and Outcomes Research (ISPOR) Task Force on Indirect Treatment Comparisons (1).
Following the ISPOR task force definitions, ‘indirect treatment comparison’ and ‘mixed treatment comparison’ are both types of network meta-analysis. Indirect treatment comparison is used to describe the analysis of networks that do not contain any loops; mixed treatment comparison is used to describe the analysis of networks that do contain loops. In Figure 1, diagrams A and C both illustrate indirect treatment comparisons, and diagram B illustrates a mixed treatment comparison. In diagram B, treatments A and B can be compared using direct evidence from AB trials, or indirect evidence via the BC and AC trials – hence, overall, the evidence for A versus B is a mix of the direct and indirect evidence.
A short history of network meta-analysis
A simple method for indirect treatment comparison was first introduced by Bucher et al. in 1997 (2); Bayesian methods suitable for indirect treatment comparison or mixed treatment comparison were published by Lu and Ades in 2004 (3). Since then, the use of network meta-analysis has risen steadily (4) and many health technology assessment agencies now accept network meta-analysis, including England’s National Institute of Health and Care Excellence (NICE).
Statistical methods for network meta-analysis are continually being developed and Quantics can provide advice on the best choice of methodology for both simple and complex networks. Our recent work includes using a three-level hierarchical network meta-analysis model to account for different doses and classes of drugs. This project included over 50 studies and 30 treatments and we applied network meta-analysis to several different outcomes. For another recent project, data was available from several different time points. We used a longitudinal network meta-analysis model to simultaneously synthesize all of the data and provide estimates of efficacy at different time points.
Further information
We hope you’ve found our first post informative. If there are any particular topics you’d like to see covered in the future then please let us know and make sure you have a look at our publications, presentations and posters which you can find here.
If you are looking for an in depth intro to network meta-analysis YHEC and Quantics run joint courses – currently available in-house, on request.