Understanding Absolute and Relative Potency Assays for Optimal Results
Relative. Thanks for reading…But wait a moment! Have you ever stopped to ask why relative potency (RP) assays are the most common potency assay? Perhaps there are cases where absolute potency (AP) would be better? Indeed, Quantics occasionally come across clients who continue to use AP for their assays. Are they incorrect?
Potency is, put simply, a measure of how much of an effect a given amount of drug has. A very potent drug would need only a small amount to produce a large effect, while taking a lot more of a less potent drug could elicit a far smaller effect.
There are several different ways to measure potency. A common example might be the LD50, which is the amount of a substance it takes to kill half a given population and is often used in studies of toxicity. Sodium Cyanide, for example, has a LD50 of 6.4 micrograms/kg in rats, while table sugar has a murine LD50 of nearly 30 g/kg. That is, on average, 30g of sugar would kill about as many rats as 0.0000064g of a spy’s last resort.
Key Takeaways
- Relative potency assays are the gold standard because they measure the test sample against a reference under the same conditions, significantly reducing variability caused by biological or experimental factors compared to absolute potency assays.
- Although absolute potency assays are more vulnerable to variability, they can be useful when maintaining a reliable reference standard is difficult, such as when the standard deteriorates quickly, avoiding the need for frequent resource-intensive bridging studies.
- While both relative and absolute potency have roles depending on the specific circumstances of the assay, relative potency is typically the better choice for regulatory acceptance and consistency, minimising failed assays and resource wastage.
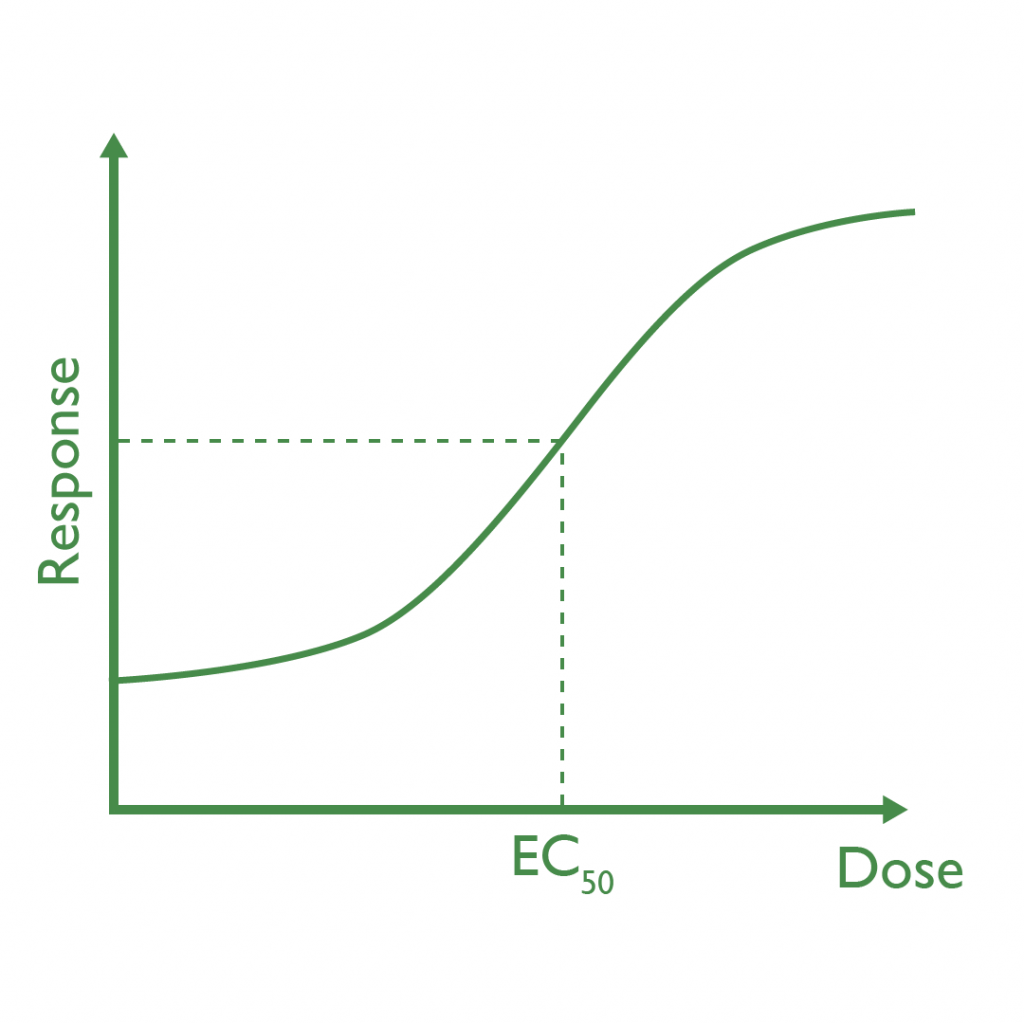
Most of the time, of course, we are more concerned with preventing deaths rather than causing them, so the potency of pharmaceuticals is more often measured using either the EC50—the dose required to observe 50% of the maximum response to the drug—or the ED50: the dose required for 50% of a tested population to experience a therapeutic effect from the drug.
To make things that little more confusing, if the drug is inhibitory—it stops something from happening—then the EC50 becomes the IC50. So, if your drug prevented a protein binding to a receptor, then you would measure its IC50. Conversely, if your drug promoted that binding, then you would measure its EC50.
To determine the potency of a drug, we typically perform a potency assay. An assay is just any analytic procedure, which sometimes takes place in live subjects (so-called in vivo assays), but take the form of laboratory experiments (in vitro assays) more commonly.
In vitro assays often measure endpoints such as luminescence and optical density, but the details of assay procedure are for another time. What matters here is what measuring those endpoints tells us: the potency.
The most obvious way to measure the potency is, well, just to measure it! You can perform your assay procedure over whatever range of doses you choose, and measure the response each elicits. From that, you can then calculate whichever measure of potency is right for you, and Bob’s your uncle! This is an absolute potency assay.
That’s all well and good, until you go to repeat the experiment. Perhaps on the second run, the responses you measure are all 10% lower than in the first run. Is your drug suddenly 10% less potent? Perhaps, but more likely you added just a bit too much solvent, or the lab was just a bit colder than during the first run. Realistically, it could be any of these, so you have to allow for a large amount of variability when analysing your results. It can, therefore, be very difficult to find the accurate, precise value for the potency of a drug required by regulators using this method.
Biological experiments are, due to the extreme complexity under the hood, often extremely variable. While we should aim to reduce this variability as much as possible in assays, some will always remain. The best course of action, therefore, is to lean into it. This is where relative potency comes in. We’ve discussed the gory details of RP elsewhere, but, in short, the idea is that you measure the potency of your test sample and that of a reference sample at the same time. How much more or less potent the test sample is at a given dose is then the RP, broadly speaking.
The important thing here is that the measurements are taking place at the same time, under the same conditions. So, ideally, if the same 10% shift in responses happened between runs of a relative potency assay, both reference and test samples would have their responses shifted by the same amount. The RP would, therefore, be unchanged as the difference in potency of the test sample relative to the reference would remain the same.
This property of the relative potency means that, while some variability will always remain, it will be much reduced when compared to a measure of absolute potency. This justification for the use of RP over AP is cited in guidance stating “Because of the inherent variability in test systems (from animals, cells, instruments, and reagents, and day-to-day and between-lab variations), an absolute measure of potency…may not be available. This has led to the adoption of the relative potency methodology.”
Is there any reason one might choose to use AP? While rare, there are cases where RP might prove problematic. Most of these revolve around the reference standard, which might, for example, deteriorate quickly meaning resource-intensive bridging studies would be required on a regular basis. The benefit of avoiding the need for a reference standard in this case could outweigh the cost of the extra variability brought by AP.
As always, no two assays are alike, and the choice between RP and AP will depend on your exact circumstances. That being said, RP will be the optimal choice more often than not due to the decreased variability of RP compared to AP, which is the reasoning behind its inclusion in regulatory guidance as the preferred methodology. AP does have its uses in cases where the reference standard is difficult to work with, but there are few circumstances where the cost of increased variability in extra failed assays—and therefore wasted resources—is outweighed by any benefits AP might bring.
The team at Quantics has vast experience and can advise you on the right choices for your bioassay. For more information, visit our bioassay services page, or get in contact here.