
Bootstrap method in dose-response modelling
In a previous blog, we looked at fitting dose-response models to quantal data in ecotoxicology scenarios. To recap, quantal data refers to data where the response variable takes a binary value. A number of organisms are exposed to a dose of test substance and then after a set period of time the number exhibiting a specific response (mortality, immobility, etc.) are counted. This is used to calculate a probability of response (or response rate) for the dose; the process is then repeated for multiple concentrations.
Key Takeaways
- Quantal dose-response data are binary outcomes summarized as response rates across doses.
- Probit models can estimate EDx values, including the ED50 (50% response dose).
- Bootstrap confidence intervals can better reflect variability across containers and datasets.
Once a response rate has been calculated for multiple doses a model can then be fit to the dose-response data. There are several options for models which can be fit at this point; in this blog we use the probit model to fit the response rate to the \(\log_{10}\) of the dose.
The purpose of this model is to find the EDx dose, the dose at which an x% response is observed. Here we focus on the ED50: the dose at which a 50% response is observed.
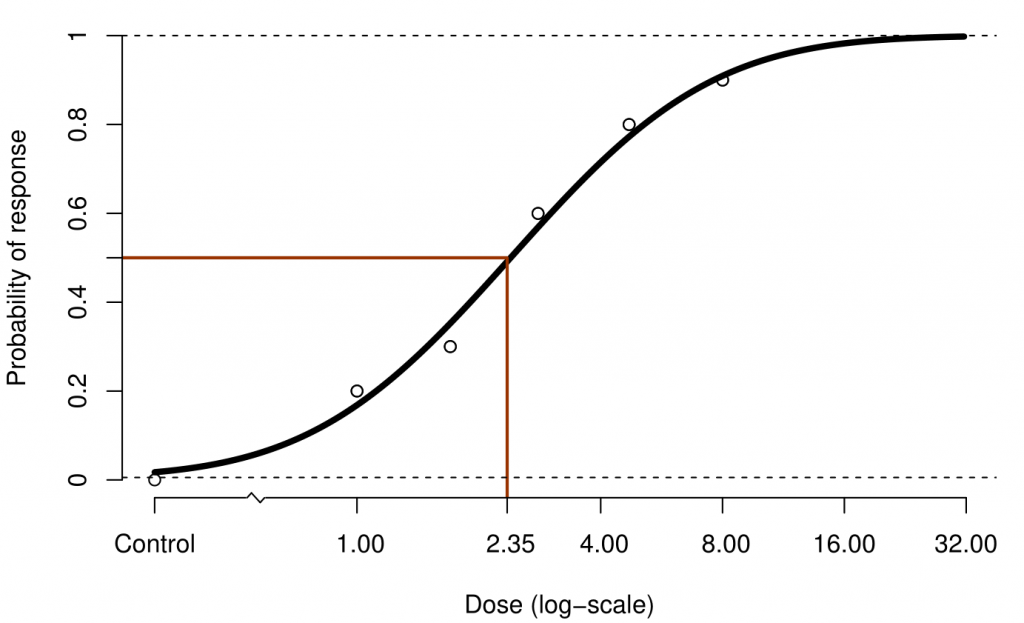
Figure 1: A plot of 6 response rates on the log dose scale for simulated data. A probit curve is fitted to the data and the EC50 is marked.
A key assumption in dose response modelling problems is that the probabilities of organisms responding are independent of each other. This assumption will often not hold when the organisms are housed together in containers, in which case the organisms can affect each other’s responses. The likelihood of this can be reduced using experimental design e.g. by housing males and females in separate containers.
Additionally the containers may differ from each other in some way. It is common for multiple containers to be exposed to the same dose of product; each container constitutes a measurement of the response rate, and taken together they can be pooled and an overall response rate is calculated. The probit model assumes that the response rates are the same within a single dose.
The graphs below give two simulated examples of this kind of experiment. For each dose there are four containers each giving their own response rate. These can be pooled to give the overall response rate to which the model is fit.
You may notice that in both cases the overall response rates at each concentration are the same, and therefore the calculated EC50 is the same, but the individual response rates are far more varied in the second example. The probit model assumes that the individual response rates are distributed binomially around the overall response rate. If this is not the case then you have extra-binomial variation. In the specific (and more common) case where the variance is larger than expected this is called over-dispersion.
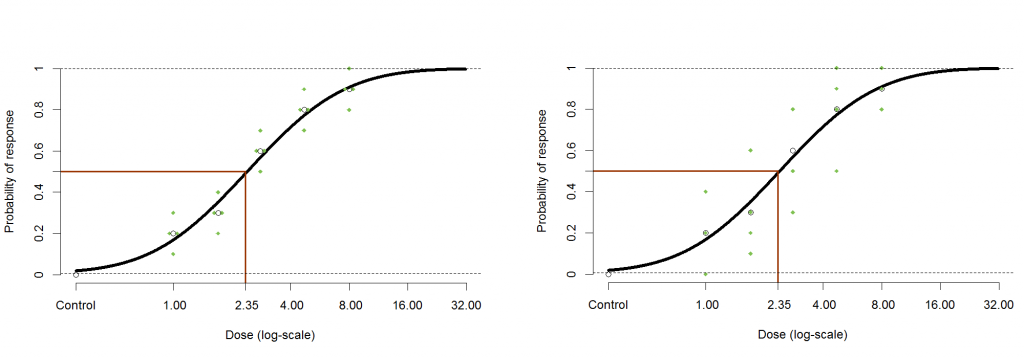
Figure 2: A plot of two datasets that both produce the same EC50 under a probit fit. The second dataset exhibits greater variability when compared to the first.
It is possible to test for over-dispersion by fitting the binomial distribution to your data, but this may not produce useful results. There may not be enough containers to produce a reliable statistical test, and either way it does not tell us what to do about the greater variability for the model.
How can we take this greater variability into account through the model? In our example it is clear that as the variability of the data is larger for the second set of data, then the confidence interval of the EC50 should be wider. In common statistical packages no adjustment to the model will be made by default, so the user must take care to ensure their model is adjusted appropriately.
One way of dealing with the problem recommended in the OECD guidance [1] is to use the bootstrap method for calculating the confidence interval. The bootstrap method treats the dataset as a distribution to be sampled from with replacement in order to create a new dataset; the probit model is then fit to this dataset to retrieve an EC50. This process is repeated thousands of times in order to build a new distribution that reflects that of the EC50. The 95% confidence interval can then be easily calculated by finding the 2.5% and 97.5% quantiles for this data. Because we sample the containers the organisms are held in, and then sample from the organisms within those containers, the width of this distribution increases as the variability of the data increases.

Figure 3: Graphs showing the theoretical distribution for the EC50 (delta method) and histograms of bootstrap results for low and high variability data respectively. The EC50 and 95% CI are marked in each case

We have calculated the 95% CIs for the EC50 for both the datasets above with the delta method and the bootstrap method. The table above shows how the confidence limits change for the different methods. The delta method produces the narrowest confidence interval. This method uses the variances of the parameter estimates to calculate the confidence interval which only takes into account the pooled response rate at each dose, not the response rate of individual containers. As a result the confidence intervals are the same for both datasets so we’ve only put a single row in the table. When the bootstrap method is applied to the low variance dataset it produces a confidence interval only slightly wider than the delta method. When applied to the high variance dataset it produces a noticeably wider interval which is what we expect.
The advantage of the bootstrap method is that it allows the data to inform the confidence intervals directly, this is why it produces CIs appropriate to the dataset used. Another benefit is that unlike the delta method, it does not automatically produce symmetric confidence intervals.
In our previous blog we dealt with probit with a background parameter and noted that the introduction of this parameter complicates calculation of confidence intervals. Another advantage of the bootstrap method is that can just as easily calculate confidence intervals for background rate adjusted models as it can in the regular case. If using the delta method, we would have to use a new formula to calculate the EC50 variance.
[1] Current Approaches in the Statistical Analysis of Ecotoxicity Data
Current Approaches in the Statistical Analysis of Ecotoxicity Data





