Bootstrapping in the Biosciences: A Guide
The idiom “to pull oneself up by their bootstraps” originated in the late 19th century. At first, it implied impossibility, but has since shifted to mean advances achieved through grit, determination, and hard work, often in business or in one’s career. Thankfully, the statistical method – bootstrapping – named for the idiom rarely requires such hard graft, at least on the part of the statistician. Efron, the American statistician who first documented the methodology, states only that the reason for the name “will become obvious” in his 1977 paper Bootstrap Methods: Another Look at the Jackknife.
Perhaps he was referring to making the most of the resources and information you have available. Bootstrapping is a method of squeezing the pips out of a single data sample when it is difficult or impossible to obtain multiple samples. And, far from being a helpful hack, bootstrapping methods can provide real advantages over other approaches, and are widely used across STEM fields. Here, we will examine some of the theory behind bootstrapping, and highlight how the methodology is used in the life sciences to help you understand what your statistician is doing.
Key Takeaways
- Bootstrapping is a resampling method that uses a single dataset to simulate many “new” samples by drawing observations with replacement, allowing estimation of statistics and their variability when repeated sampling is impractical.
- Because bootstrapping makes minimal assumptions about the underlying distribution, it is particularly useful for small samples, non-normal data, and settings with complex or correlated outcomes, such as clinical or bioassay data.
- Bootstrapped confidence intervals can be built using percentile-based methods that avoid normality assumptions, but any bias present in the original sample will be propagated through the bootstrap unless it is assessed and corrected for.
What is Bootstrapping?
Whenever we conduct statistics, we make measurements to determine information about the world around us. We can refer to these measurements as samples. A simple example might be measuring the average height of a group of high school students, which gives us information about how tall high school students might be.
A founding principle of statistics is, of course, that our sample will show variability about the “true” or population value. So, we might want to find out the average height of students in a particular school. If we take only a single sample, then our estimate will show a lot of variability about the population value depending on, say, whether we choose a group of freshman girls or a group of senior boys. So, we can take repeated samples, and find the overall average. The more samples we take – the more groups of students we measure – the closer our final average will be to the “true” population value.
But what if it’s impractical or even impossible to perform repeat sampling? That’s where bootstrapping comes in. Bootstrapping is a method of using a single sample to simulate repeated sampling.
Let’s look at an example of the bootstrapping methodology. Imagine we want to find the average height of a high school student in a particular city, but we only have the funding for one afternoon’s field work. This means we are only able to measure the height of one class of 20 students, whose heights in centimetres are shown in the table below.
|
184 |
163 |
185 |
175 |
155 |
|
164 |
168 |
185 |
162 |
160 |
|
153 |
173 |
181 |
175 |
176 |
|
172 |
152 |
153 |
164 |
176 |
To generate the bootstrapped samples, we draw data points at random from our measured data, typically until we have generated a sample of the same size as our original data set. The idea here is that each of these bootstrapped samples represents a sample which we could have obtained by measuring the heights of more students.
When we have formed a sample, we find its mean. This is then repeated, typically between 1,000 and 10,000 times. Our final answer is the overall average of the mean height within each sample. As with any other set of samples, we can use the bootstrapped samples to calculate measures of variability, such as the standard deviation, and use these to construct confidence intervals on the final answer – we’ll cover this in more detail later.
Importantly, we draw from our original measured data with replacement, like drawing a raffle ticket and putting it back into the bucket. This means that each data point could potentially appear in each sample more than once. If we drew our values without replacement – if each data point could only appear in each sample once – then, assuming our bootstrapped sample is the same size as our measured sample, we would draw the exact same sample every time. Needless to say, this would rather defeat the point of the exercise!
In our example, we took 1000 bootstrapped samples. Four randomly selected samples are listed below:
Sample 21:
|
155 |
185 |
155 |
173 |
164 |
|
176 |
162 |
173 |
162 |
185 |
|
181 |
168 |
153 |
175 |
163 |
|
173 |
164 |
162 |
152 |
173 |
Mean = 167.55
Sample 666:
|
52 |
155 |
153 |
162 |
155 |
|
162 |
185 |
175 |
168 |
152 |
|
155 |
160 |
168 |
172 |
176 |
|
175 |
175 |
184 |
173 |
184 |
Mean = 167.05
Sample 680:
|
155 |
185 |
155 |
173 |
164 |
|
176 |
162 |
173 |
162 |
185 |
|
181 |
168 |
153 |
175 |
163 |
|
173 |
164 |
162 |
152 |
173 |
Mean = 167.90
Sample 725:
|
155 |
185 |
155 |
173 |
164 |
|
176 |
162 |
173 |
162 |
185 |
|
181 |
168 |
153 |
175 |
163 |
|
173 |
164 |
162 |
152 |
173 |
Mean = 169.70
Notice how all of these four samples contain repeated values, which result from the process of sampling with replacement. This is also evident in the variability in the mean: recall that we would expect this to be the same for all samples if we sampled without replacement.
Once sampling is complete, the mean of each sample is calculated. A histogram of the mean of all 1000 samples is shown below:
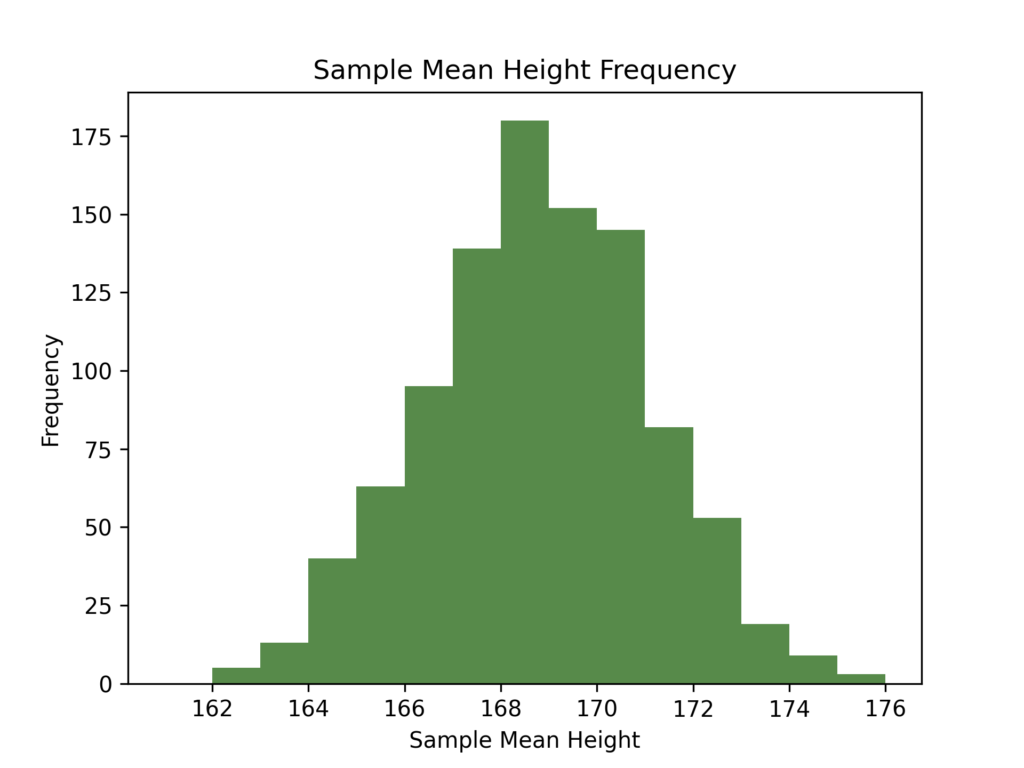
We can see that, despite the quite limited data set from which the samples have been drawn, there is a reasonably large amount of variability in the sample means.
Despite this, the mean of the means in this case is 168.78cm, which is noticeably close to the original sample mean of 168.80cm.
Bootstrapped Confidence Intervals
However, if you’re a long-term reader of the Quantics blog, you’ll know that we shouldn’t stop at the point estimate which is the sample mean. Instead, we should quote a confidence interval. We won’t go into the details of what the confidence interval means here – we’ve covered that in three-part detail elsewhere – but we will take a look at how you might construct a confidence interval when you’re using a bootstrapping methodology.
In situations where we are looking at the mean with a large sample size, such as this, we would typically invoke the central limit theorem to calculate confidence intervals. We don’t usually require a bootstrap here. Nevertheless, we’ve chosen to illustrate calculating CIs using bootstrapping here as a simple example.
One approach is to treat the bootstrapped sample means as you would any other data and construct the confidence intervals with reference to a standard normal distribution. This would result in limits which are very similar to the standard approach without bootstrapping. In other cases, however, the assumption of normality might be a strong one, and we shouldn’t expect this to be the case every time we try to determine a confidence interval around an estimate. We also face the subtler issue that to construct the confidence interval by this method requires us to use the standard error. This can be problematic as we treat this as a known parameter when we are, in fact, required to estimate it from the bootstrapped data.

If we use the standard error approach to build a confidence interval with our example data, we find a range of (168.64, 168.92). This is shown in green on the plot above.
A more theoretically-sound approach is known as the percentile confidence interval. This method is almost painfully simple: we first place the sample means in ascending order. If we are interested in a two-sided 95% confidence interval, we then look at the values which represent the 2.5th and 97.5th percentiles. For our 1000 samples, these would be the 25th and 975th largest means. These percentile values then form the lower and upper confidence limits for our mean. Using this method, a 95% confidence interval on the mean we calculated above would be (168.63, 168.90), which is also shown on the above plot in orange. The percentiles of interest depend on the confidence level of the interval: if we wanted a two-sided 90% CI, we would instead look at the 5th and 95th percentile.
An advantage of this method is that it is completely independent of the underlying distribution of the bootstrapped samples, meaning we no longer have an assumption of normality. This means that we can use this method to set robust confidence intervals for parameters of whose distribution we have no prior knowledge.
We can, however, run into problems if there is a bias inherent to the bootstrapped samples – perhaps our original group of 20 students happened to be the varsity squad? This bias would percolate throughout our bootstrapped samples, which would cause problems in our confidence interval, no matter what method of confidence interval construction we use.
Indeed, we can see the influence of bias in our percentile confidence interval, which is not symmetric about the mean. This makes sense: there is no reason to expect any percentile range to be symmetric about the mean (or to even contain the mean, for that matter). For the percentile CI, bias can be corrected using the Bias-Corrected and Accelerated Percentile CI (BCA percentile confidence interval), but it is generally seen as good practice to account for bias in the original sample used for bootstrapping to minimise any effect in the final results.
There are further methods of calculating confidence intervals when using bootstrapping, such as the pivotal CI. We shall save the details of these for another time.
How Useful is Bootstrapping?
One benefit of bootstrapping in practice is that it can be used even when there are complex correlations between outcomes. For many statistical tests, we require our measurements be independent – we should gain no information from one measurement about any others in the experiment. A good example is a coin flip – the result of one coin flip tells us nothing about the next.
As with all assumptions, however, independence often falls down when faced with the complexities of reality. For a simple example, imagine we were conducting a clinical trial which examined the effectiveness of a certain treatment at reducing the growth rate of tumours. As we are interested in the direct effect of the treatment on the tumour, it makes sense to conduct the analysis on a tumour-by-tumour basis, rather than looking at the outcomes for the subjects.
This, however, presents a problem. A single subject can have multiple tumours, and the growth of tumours associated with the same subject is inherently correlated. This means that it is unlikely that methods which assume independence will hold up.
This is where bootstrapping comes in. As a non-parametric methodology, bootstrapping does not require measurements to be independent to give consistent inference.
Let’s say our trial examined 50 subjects with up to 5 tumours each. So, to conduct our analysis, we draw subjects with replacement: we draw subjects rather than tumours to maintain the correlation structures in the data. The growth rate of each tumour afflicting the selected subjects is then included in an estimate of the mean growth rate for that sample.
This process is repeated several times, providing multiple estimates of the growth rate. This can then be used to determine confidence intervals using the methods described above (for example, the BCA percentile confidence interval) and to perform inference as to the efficacy of the treatment.
Bootstrapping in Clinical Trials
As always, there are caveats. Bootstrapping is, in effect, trading off a larger quantity of calculations against the complexity of traditional methods. This means bootstrapping represents a far more computationally intense methodology. In the modern age of easily accessible fast computing, this may not provide a significant obstacle. Nevertheless, it is an important consideration when choosing a bootstrapping technique.
Another key consideration is that of bias. Bootstrapping relies heavily on the original data which is used to draw samples. This means that any bias in this initial sample will be present throughout the bootstrapping process unless corrected for. It is, therefore, crucial that any bias is evaluated before the bootstrapping process begins.
For such a simple technique, bootstrapping can provide some large benefits. It provides a route to robust statistical inference when it is impractical or impossible to gain sufficient sample size, or when assumptions about the underlying distribution of data are not valid. These are just a few of the reasons why bootstrapping is a vital string in our statistical bow.