Multiplicity in a Clinical Trial: Why is it Important?
This blog introduces the concept of multiplicity, why it is important and offers some techniques for dealing with the issue. When planning a clinical study, lots of thought is put into what to measure – i.e., which data needs to be collected, how it should be analysed. This leads to the definition of so-called endpoints. In confirmatory clinical studies, primary endpoints are typically statistically tested using hypotheses.
Multiplicity is an issue that should be controlled for in clinical studies which assess the primary endpoint in more than one way. This could mean a different way of calculation, or calculations based on several subgroups. Other cases include clinical trials which assess several primary/secondary endpoints, assess an endpoint at different time points (interim analyses), use blinded sample size re-estimation for equivalence or non-inferiority trials, or use unblinded sample size re-estimation.
Key Takeaways
- Multiplicity can occur when multiple hypotheses or endpoints are tested within a single clinical trial, increasing the chance of Type I error and potentially leading to incorrect conclusions.
- Multiplicity may arise when assessing the primary endpoint in more than one way, testing multiple primary or secondary endpoints, or analysing endpoints at different time points.
- Strategies to maintain the overall Type I error rate include the Bonferroni correction, Holm and Hochberg adjustments, and gatekeeping and fallback methods.
For example, consider that a pharmaceutical company has developed Drug A, and wants to demonstrate that it is superior to Drug B which is widely used as standard treatment. A trial design could include two arms (one for each drug), and a measure of efficacy (such as reduction of a clinical score from baseline at 4 weeks).
The hypothesis to be statistically tested is set up as “null hypothesis” vs “alternative hypothesis”, with the aim to reject the null hypothesis (“Drug A is only as good, or inferior to Drug B”) in favour of the alternative hypothesis (“Drug A is better than Drug B”).
The alternative hypothesis may or may not be true; tests and sample sizes will be determined in a way such that:
- If the alternative hypothesis is true (drug A is better than drug B) a rejection of the null hypothesis is likely.
- This is described as the power of the study, and is linked to a large enough sample size.
- If the alternative hypothesis is wrong and drug A is, at best, only as good as drug B, a rejection of the null hypothesis is unlikely.
- This is the so-called “Type-1” error, and typically set as 2.5% for one-side tests, or 5% for two-sided tests. This threshold is also referred to as significance level, or as alpha.
Note that this is all about how likely the tests are to give the correct result. More about the general structure of hypothesis testing can be found here.
In the example above, we would be interested in a one-sided test (we are only interested in Drug A being superior). The typical significance level would be 2.5%. If the null hypothesis is true, there will be a chance of 2.5% to (wrongly) reject the null hypothesis, and wrongly claim that Drug A is superior to Drug B.
Now, if more than one hypothesis is tested, the problem of multiplicity arises. With every new test the chance of rejecting at least one correct null hypothesis increases further. If multiplicity is not controlled for, and if both null hypotheses are actually true and independent from each other, then there is a 5.1% chance (= 1 – 0.975*0.975) that at least one of the null hypotheses is wrongly rejected. In other words, the chance of claiming something wrong increases. This is the reason why regulators want to see a strategy for controlling multiplicity.
When can multiplicity arise?
Typical situations for multiplicity are (amongst others):
- The primary endpoint is assessed in more than one way.
- This could mean a different way of calculation, or calculations based on several subgroups.
- Several primary/secondary endpoints are assessed.
- One endpoint is assessed at different time points (interim analyses).
- Blinded sample size re-estimation for equivalence or non-inferiority trials.
- Unblinded sample size re-estimation.
Assessments “for information only” are absolutely fine and do not contribute to the problem of multiplicity. However, care needs to be taken when conducting interim analyses, since it might lead to a change of conduct of the study, even if no formal hypothesis is tested at the interim analysis.
Methods to control for multiplicity
We strongly recommend that you consult a suitably experienced statistician about this as it can get quite complex. Common methods include:
- If more than one primary endpoint is tested, they can be treated as co-primary endpoints. This means that the study will be successful only if all of the primary endpoints are successfully tested (i.e., all of the null hypotheses are rejected).
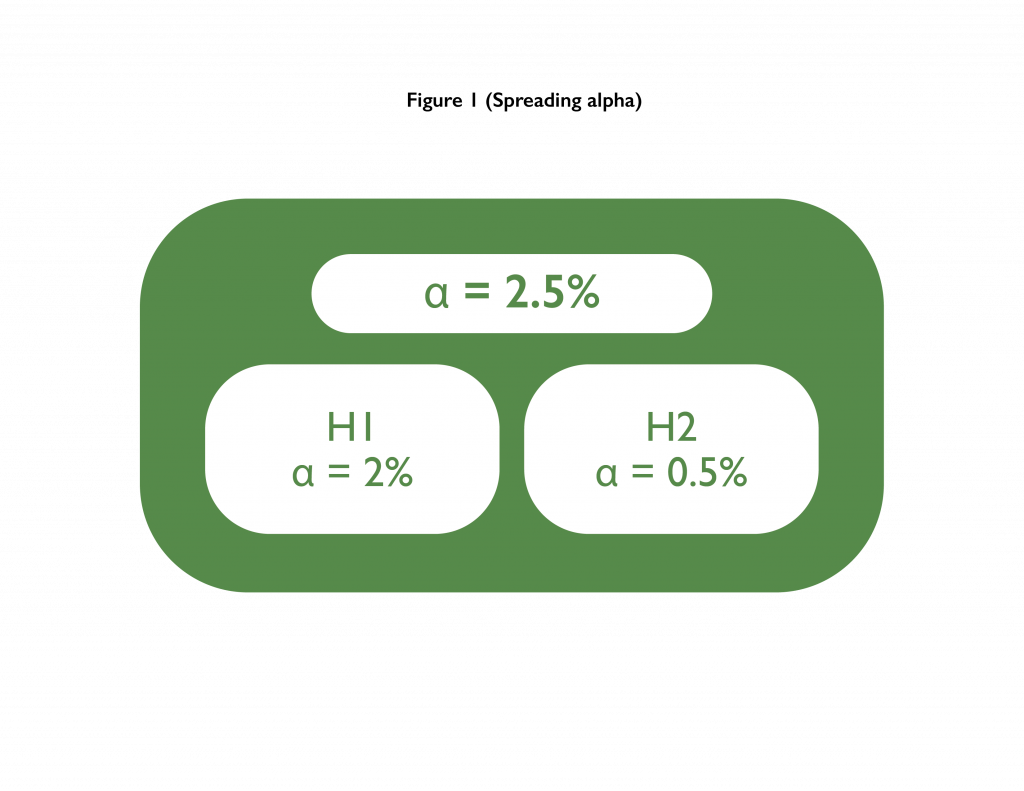
- Bonferroni correction/spreading alpha: Here the “alpha is spread across multiple tests”. Alpha stands for the Type-1 error. In our example from above, if two hypotheses were to be tested, then the alpha of 2.5% could be spread between them. E.g., both could be tested at 1.25%, or one could be tested at 2% while the other one could be tested at 0.5%.
- Holm adjustment with n hypotheses: The idea is to make it very challenging for the best performing test to pass, and then to gradually ease the challenge. Failure for one test would imply failure for all other tests not yet evaluated for success.
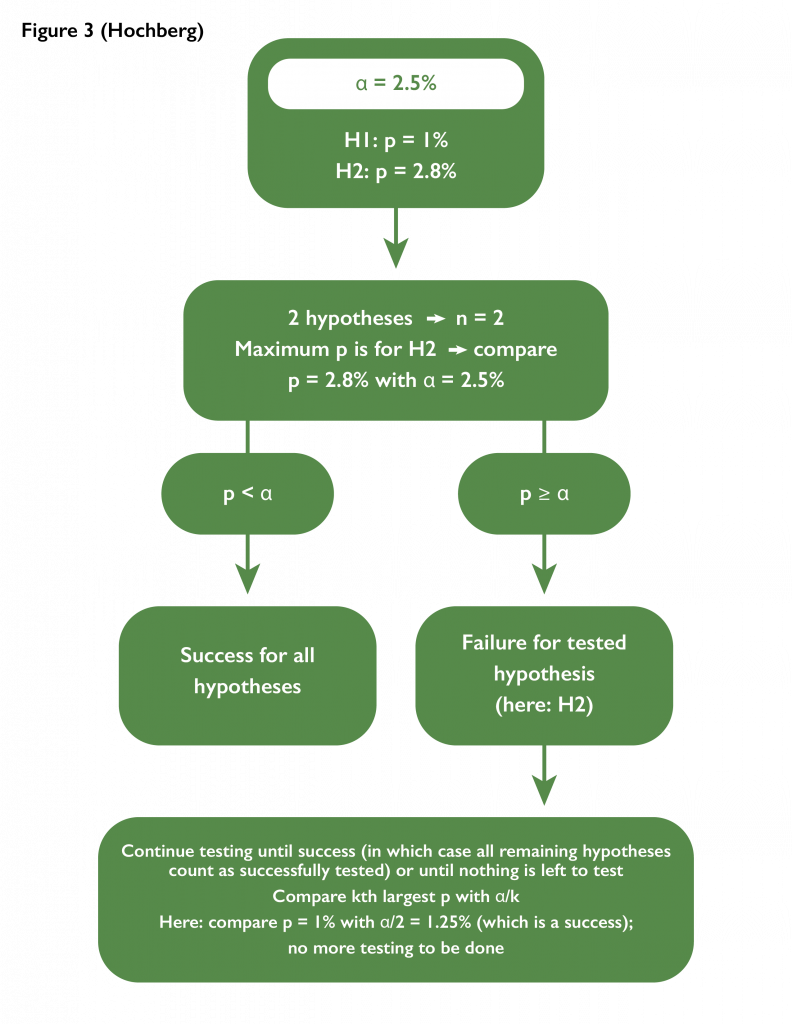
- Hochberg adjustment with n hypotheses: The idea is to require the worst performing test to pass. Success for one test would imply success for all other tests not yet evaluated for success. If a test fails, the next worst performing hypothesis would be tested with a more challenging threshold.
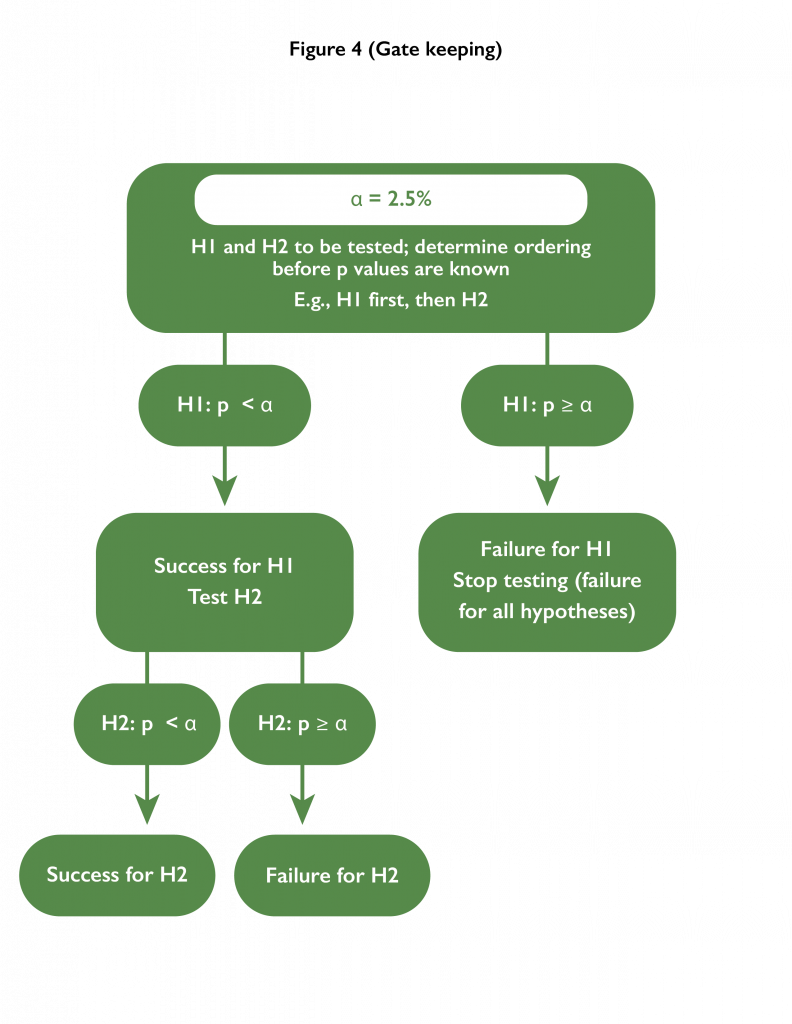
- Gatekeeping: An ordering of testing the hypotheses is pre-specified. Each hypothesis is tested at the alpha level; however, as soon as a test fails, hypotheses further down the hierarchy remain untested.
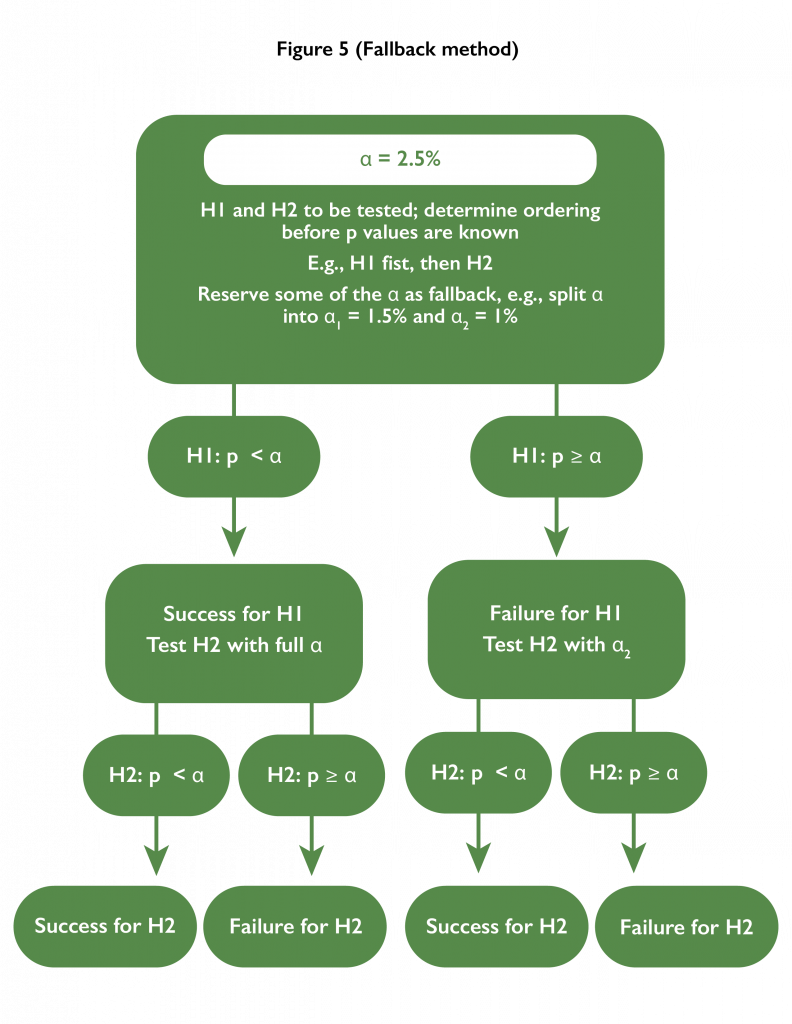
- Fallback method: An ordering of testing the hypotheses is pre-specified. The first hypothesis is tested at a level lower than the alpha level. If successful, the second hypothesis is tested at the full alpha level. If unsuccessful, the second hypothesis is tested at the difference of alpha and the first testing level.
This list is by no means exhaustive, and in some situations, such as adaptive trial designs which allow for changes to the study while it is being conducted, bespoke strategies may be required in order to account for the impact of potential adaptations on hypothesis testing.