
Fitting Algorithms: The BEBPA Sessions
This is the second mini blog responding to the software discussions at the BEBPA US 2022 conference. Blog One: Formulae can be found here.
The key driver for these sessions was the experience that many have had of different software and different versions of the same software giving different results. This causes problems with RP values, and system and sample suitability criteria when transferring assays to different labs.
Here, we’ll focus on one cause: differences in model fitting algorithms.
Blog Two: Algorithms
In part one we showed that the 4PL formulae can be expressed in several different mathematically equivalent ways called parameterisations. However, even when the parameterisation is taken into account, people do find differences in the results between software systems and versions for the parameter estimations and therefore the RP. At the BEBPA conference there was some suggestion it might be rounding, or convergence.
Key Takeaways
- Differences in relative potency results between software systems often arise not from the 4PL formula itself, but from how each package fits the curve — particularly how its optimisation algorithm handles convergence and stopping rules.
- Iterative methods (such as Levenberg–Marquardt) can converge to local rather than global minima, or stop too early, leading to unstable or inconsistent results for similar datasets or between software versions.
- Robust tools like QuBAS mitigate these issues by using dual optimisation algorithms to confirm the global minimum, avoiding instability and ensuring consistent, reliable bioassay results across labs and time.
Fitting a curve or a line to a data set involves adjusting the parameters so that the best fit is obtained. There are various ways of defining “the best fit”, but in bioassay this is always taken to be the curve fit where the sum of the squares of residuals is minimal.
For a linear model there are three parameters to consider: the slope, intercept and the sum of squares. In this case the best fit can simply be calculated.
See for example: https://www.varsitytutors.com/hotmath/hotmath_help/topics/line-of-best-fit
Unfortunately, for a 4PL curve this is not possible. In simple terms the method involves starting with “an educated guess” of the parameters, calculating the fit, then adjusting the parameter estimates in little steps guided by the result of the previous adjustment. This is called an iterative technique. The aim is to continue taking little steps to the point where any further change in any parameter results in a less good fit, i.e. the residual sum of squares is minimal. This is called convergence – the iterative process has converged on the best answer.
There are many ways (algorithms) that can be used to derive estimates of the parameters but not all work very well. How well they work depends on the data you have and where you start your iterative journey. The algorithm efficiency also depends on the parameterisation of the formulae, which is why there are different parameterisations quoted. (The most common algorithms are based on a process called maximum likelihood and seek a maximum point, not a minimum, but don’t worry about that.)
What does this imply for software?
To help understand this, let’s look at some 3D illustrations. They don’t correspond to the actual process – for a 4PL that would need visualisation of a 5-dimensional space and my brain can’t do that!
Generally, wherever you start from, convergence will be achieved and a minima will be found (the blue pit).
Receive every Quantics blog as soon as it’s released
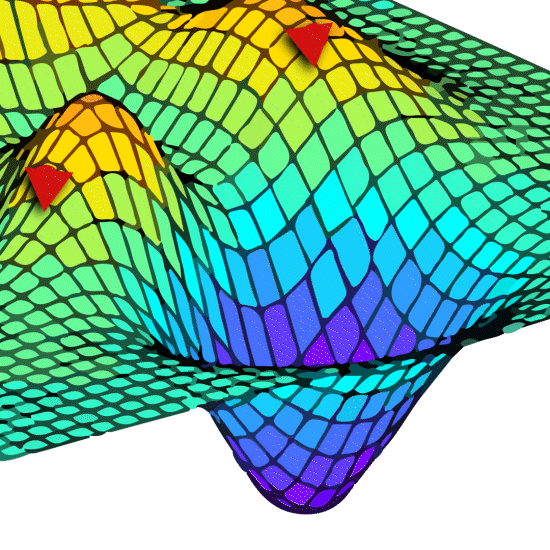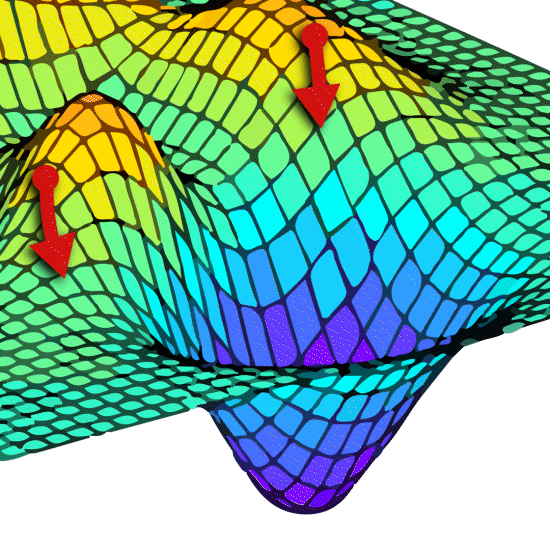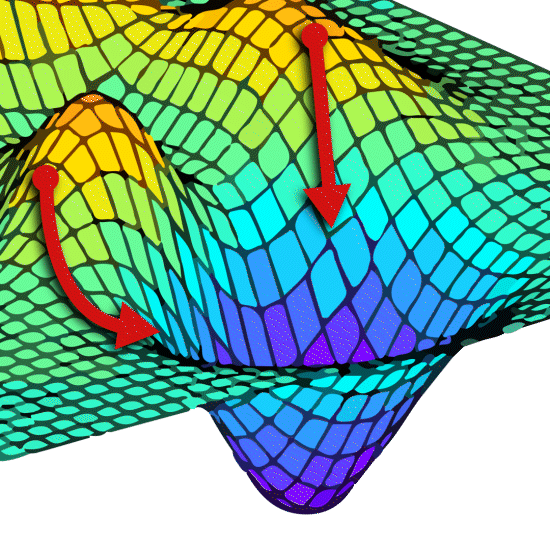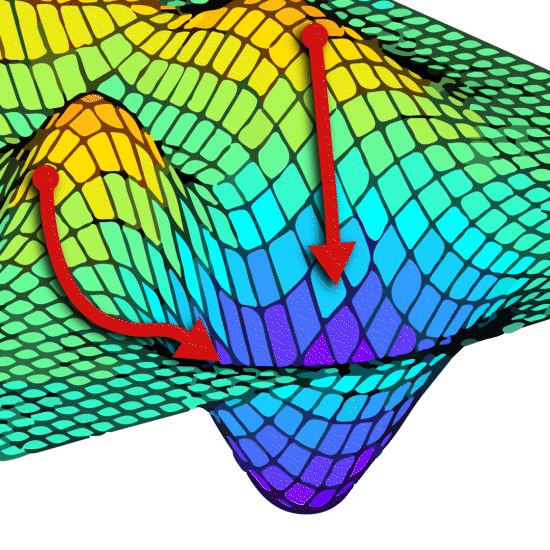
Where you start from will impact how many steps are needed and therefore how long it takes.
In practice, if the minimum is not found reasonably quickly, most software limits the hunt to a certain number of steps, or stops when the improvement in fit from step-to-step is very small. The software assumes that the fit at this point is good enough.
Of course, if this early stopping is triggered, this will produce a different result depending on where you started from. This was discussed at the BEBPA session, with several contributors (correctly) suggesting this was the cause of many of the differences seen. Generally, the differences seen in the parameters and RP because of this are small.
Occasionally though, a start point may be chosen such that the stopping point is reached (because the change from step to step is very small, or the maximum number of steps is reached), but the minimum point is, as it were, a long way away. In these cases, there may be significant differences seen in the results between versions and software types.

Occasionally there is no minimum point to be found anywhere. This is called a singular fit or non-convergence – typically the best fit has a slope factor or upper asymptote of zero or infinity. This should be reported as no fit possible because there is no information to determine what fit parameters to report, but most software (but not QuBAS) just outputs the parameters when the software stopping limits are reached which can be very misleading.
More trouble
All that is complex enough but there is another major problem that none of the contributors to the meeting mentioned. For both the 4PL and 5PL models there can be several minima. Of course, only one is correct. These are known as local minima and the lowest one is the global minima.
Now there is a real problem. Where you start from not only alters the time it takes, it can make you miss the right answer completely.
In this situation you can end up with small or large differences in parameters or RP values or parallelism failures between software. This can also cause unstable results for near identical datasets. If the starting point for a particular dataset is, for example, at the top of the little hill in the foreground, the results will be very unstable – tiny changes in the data may send the optimisation to completely different solutions, A or B. One day your results are fine, the next, where the data looks almost identical, the RP is reported as very different, or the assay fails parallelism. If the results are unbelievable you would be alerted, but what if they are believable?

Is all this a real problem?
Apparently it is. We have been told by several clients that unstable behaviour is seen from time to time in practise, and does cause practical issues. Most software we are aware of use algorithms based on the Levenberg–Marquardt algorithm, and it is known that this on its own only finds local minima. So if this is what your software does, or it is stopping too early on some occasions, then you can expect to see this sort of instability from time to time.
If you do see this happening, and would like us to examine the dataset for multiple minima, just get in touch. We are interested in this so will report back to you free!
Our QuBAS software uses two completely different algorithms for this problem and keeps on hunting to find the global minimum, so we do not see this kind of instability.
Remember that we have been looking at a 3 dimensional space. For a 4PL model it is a 5 dimensional “space”. All of the above also applies in the same way to the 5PL, but there are many more instances of local minima. And now the maths is working in 6 dimensions…..
Reliable optimisation of this type of curve fit is very complex, and it is studied in the mathematical discipline of numerical analysis.
Note that using “brute force” (a very large number of steps or very small step differences) as suggested by a couple of contributors at BEBPA has no impact on this issue.
So now we know why differences are seen between software types and versions, and why some software can appear to give odd or unstable results at times.
What can we do? How can we be sure that the results we get are correct, even on one site, let alone across sites, software types and versions? What about the suggestions made at BEBPA about bridging?
This is the subject of the final blog in this mini series.




